什么是Solr及为搜索引擎对大数据量创建索引
使用Solr实现
基于Solr实现站内搜索扩展性较好并且可以减少程序员的工作量,因为Solr提供了较为完备的搜索引擎解决方案,因此在门户、论坛等系统中常用此方案。
什么是Solr
Solr 是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务器。Solr提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展,并对索引、搜索性能进行了优化
Solr可以独立运行,运行在Jetty、Tomcat等这些Servlet容器中,Solr 索引的实现方法很简单,用 POST 方法向 Solr 服务器发送一个描述 Field 及其内容的 XML 文档,Solr根据xml文档添加、删除、更新索引 。Solr 搜索只需要发送 HTTP GET 请求,然后对 Solr 返回Xml、json等格式的查询结果进行解析,组织页面布局。Solr不提供构建UI的功能,Solr提供了一个管理界面,通过管理界面可以查询Solr的配置和运行情况。
solr是基于lucene开发企业级搜索服务器,实际上就是封装了lucene。
Solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口。用户可以通过http请求,向搜索引擎服务器提交一定格式的文件,生成索引;也可以通过提出查找请求,并得到返回结果
Solr类似webservice,调用接口,实现增加,修改,删除,查询索引库。
Solr与Lucene的区别
Lucene是一个开放源代码的全文检索引擎工具包,它不是一个完整的全文检索引擎,Lucene提供了完整的查询引擎和索引引擎,目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者以Lucene为基础构建全文检索引擎。
Solr的目标是打造一款企业级的搜索引擎系统,它是一个搜索引擎服务,可以独立运行,通过Solr可以非常快速的构建企业的搜索引擎,通过Solr也可以高效的完成站内搜索功能。
Solr类似webservice,提供接口,调用接口,发送一些特点语句,实现增加,删除,修改,查询。
solr4.x快速入门
1 下载
从Solr官方网站(http://lucene.apache.org/solr/ )下载Solr4.10.3,根据Solr的运行环境,Linux下需要下载lucene-4.10.3.tgz,windows下需要下载lucene-4.10.3.zip。
Solr使用指南可参考:https://wiki.apache.org/solr/FrontPage。
下载solr-4.10.3.zip并解压,解压后目录为:
bin:solr的运行脚本
contrib:Solr的一些扩展包,包括分词器,聚类,语言识别,数据导入处理,非结构化内容分
析等.
dist:该目录包含build过程中产生的war和jar文件,以及相关的依赖文件。我们之
前使用的solr.war实际上就是这个文件夹下的solr-4.40.war
docs:solr的API文档
example:solr工程的例子目录:
l example/solr:
该目录是一个包含了默认配置信息的Solr的Core目录。
l example/multicore:
该目录包含了在Solr的multicore中设置的多个Core目录。
l example/webapps:
该目录中包括一个solr.war,该war可作为solr的运行实例工程。
l licenses:solr相关的一些许可信息
2 使用solr内置jetty服务器运行solr
Jetty服务器是web容器,类似tomcat。
启动solr内置jetty服务器流程:
1、 启动运行example/start.jar
a) 直接在cmd命令行运行命令
b) 使用bat批处理文件运行jar包
2、 加载example/lib下面的jetty服务器
3、 Jetty服务器加载example/webaaps/solr.war项目
4、 加载索引库仓库:example/solr
Solr首页
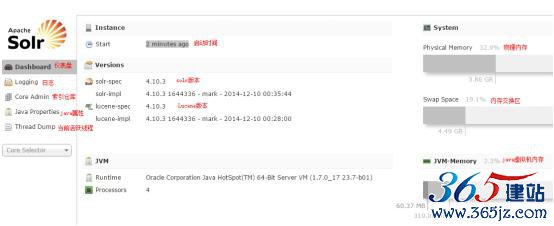
索引仓库core admin
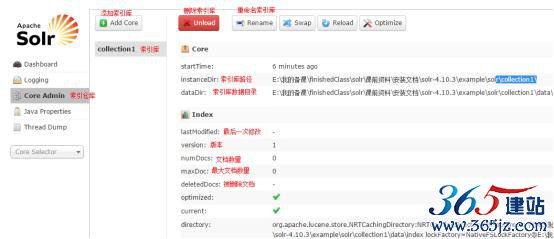
多索引库
一个core admin(索引仓库)有多个索引库collection1,collection2…..
添加第一个索引库:
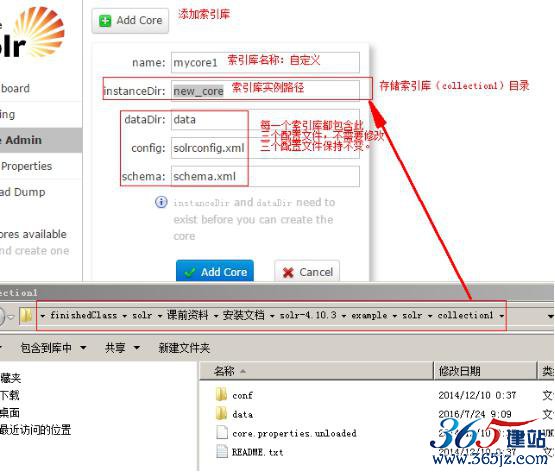
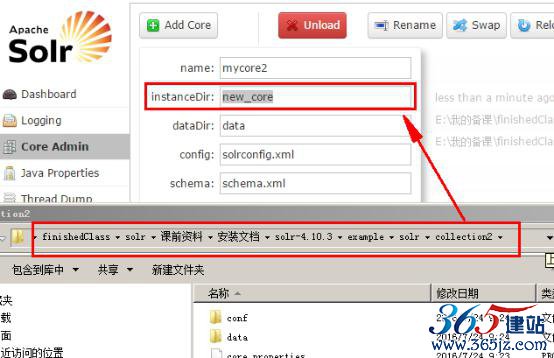

选择索引库
overView

Analysis
Dataimport
导入外部数据。导入mysql数据库商品数据。
Documents
Files
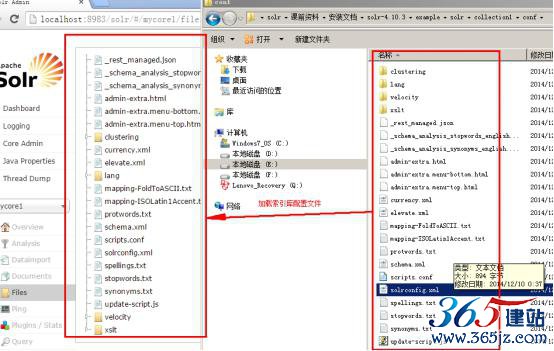
索引库配置文件拷贝,加载索引库配置文件。
Query
管理界面
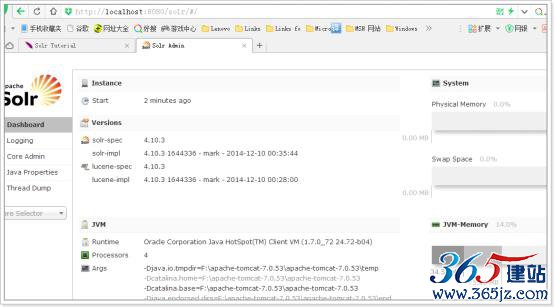
Dashboard:
仪表盘,显示了该Solr实例开始启动运行的时间、版本、系统资源、jvm等信息。
Logging:
Solr运行日志信息
Cloud:
Cloud即SolrCloud,即Solr云(集群),当使用Solr Cloud模式运行时会显示此菜单,如下图是Solr Cloud的管理界面:

Core Admin:
Solr Core的管理界面。Solr Core 是Solr的一个独立运行实例单位,它可以对外提供索引和搜索服务,一个Solr工程可以运行多个SolrCore(Solr实例),一个Core对应一个索引目录。
java properties
Solr在JVM 运行环境中的属性信息,包括类路径、文件编码、jvm内存设置等信息。
Tread Dump
显示Solr Server中当前活跃线程信息,同时也可以跟踪线程运行栈信息。
Core selector
选择一个SolrCore进行详细操作,如下:
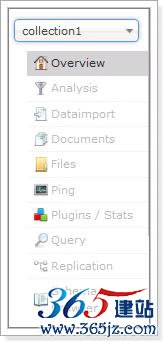
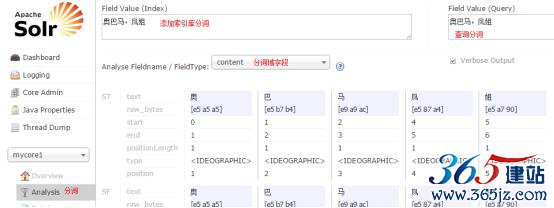
Analysis(重点)

通过此界面可以测试索引分析器和搜索分析器的执行情况。
dataimport
可以定义数据导入处理器,从关系数据库将数据导入 到Solr索引库中。
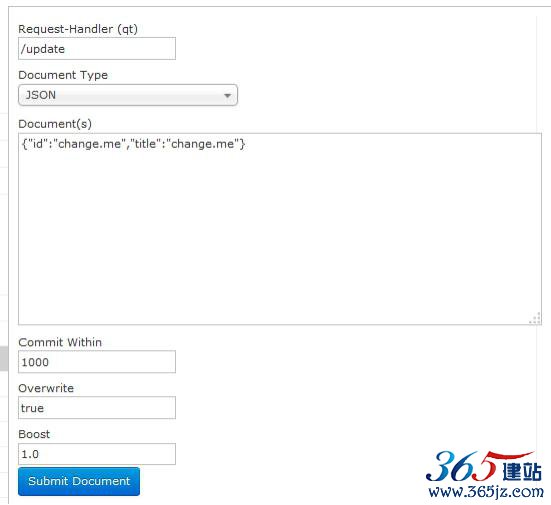
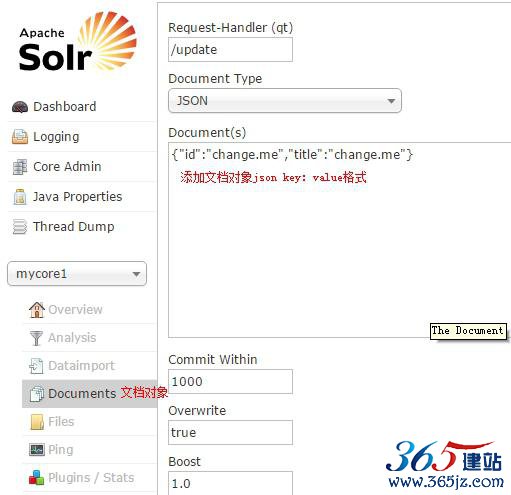
Document(重点)
通过此菜单可以创建索引、更新索引、删除索引等操作,界面如下:
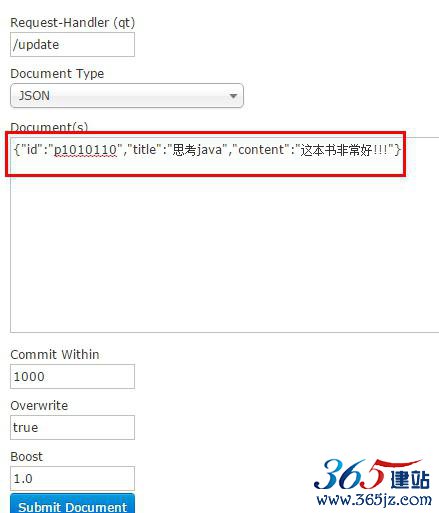
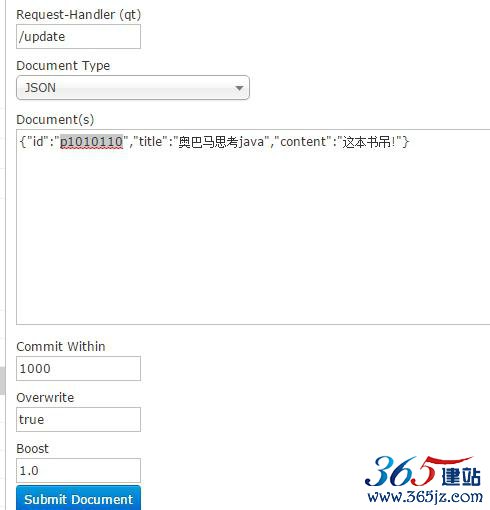
/update表示更新索引,solr默认根据id(唯一约束)域来更新Document的内容,如果根据id值搜索不到id域则会执行添加操作,如果找到则更新。
添加索引库
修改
如果Id存在,修改
如果Id不存在,添加。
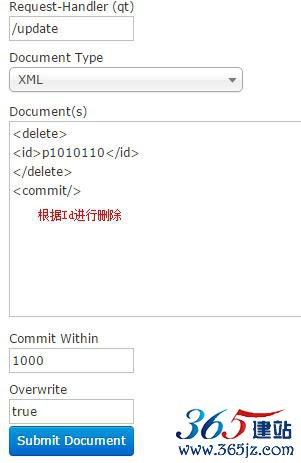
删除
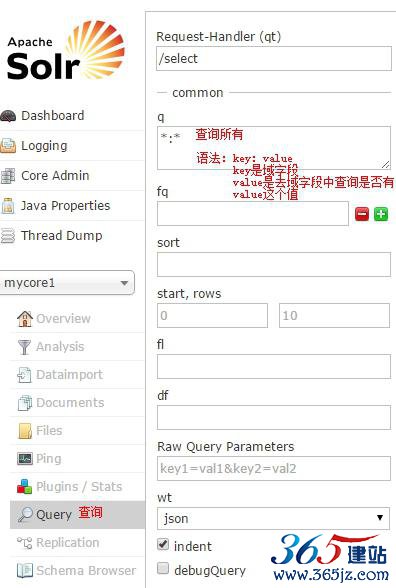
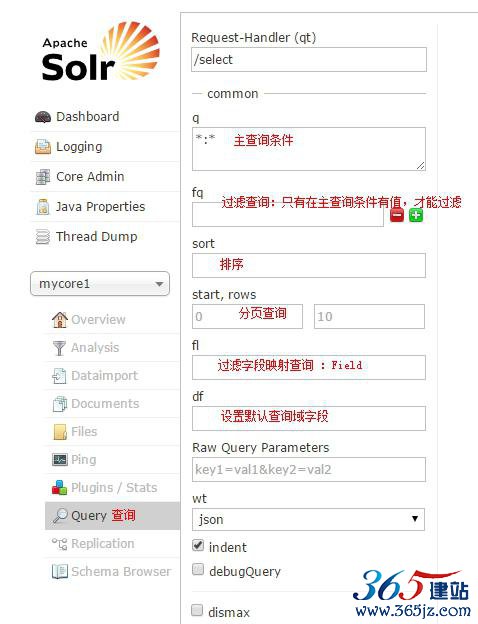
query(重点)
System property替换
Solr 支持系统属性替换,允许启动JVM在任一Solr的配置文件指定字符串替换。
语法: ${property[:default value]}
替换是有效的在任何元素或属性的文本。
这里是允许运行时决定数据目录的一个例子:
<dataDir>${solr.data.dir:./solr/data}</dataDir> 使用示例应用程序中
solr可以以这种方式启动:
java -Dsolr.data.dir=/data/dir -jar start.jar 如果没有指定
solr启动时读取 conf/solrcore.properties文件
#solrcore.properties data.dir=/data/solrindex
解析:运行时替换目录意思
注意:在solrConfig配置文件里面使用${},这是solr语法格式。
简单解释一下:
Solr.就代表solrcore索引库目录:collection1这一层目录。
顾名思义:solr.data.dir表示的意思就是collection1下面的data目录。
这是solr的一种约定,不必深究,知道solr.就是我们的索引库目录就ok。
Solrj
什么是SolrJ
solrj是访问Solr服务的java客户端,提供索引和搜索的请求方法,SolrJ通常在嵌入在业务系统中,通过SolrJ的API接口操作Solr服务

具体包括使用DataImportHandler从数据库中近实时同步数据、测试Solr创建索引的性能、以及测试Solr的搜索效率总结等。
具体搜索引擎概念、Solr搭建方法、数据库mysql使用方法,假设读者已有了基础。本文操作均是在linux上进行的。
1. Solr
1.1 Solr从数据库中读取数据并创建索引速度(使用DataImportHandler)
l 一次性创建索引在JVM内存配置为256M时,建立索引至1572865时出现Java heap异常;增加JVM内存配置至512M,设置系统环境变量:JAVA_OPTS -Xms256m -Xmx512m,能成功建立2112890条(花费2m 46s)。
平均索引创建速度为:12728/s(两个string字段,长度大约为20字符)。
l 增量创建索引
注意:近实时增量索引需要写数据库服务的时间与搜索引擎服务器时间同步(数据库服务时间先于搜索引擎服务器时间才行)。
使用默认的DIH创建增量索引速度较慢(50/s~400/s),不如全索引(1W/s),因为需要从数据库中读取多遍(1、要更新的IDs;2、每1ID去数据库中重取所有列)。
故需要更改DIH增量索引程序,以全索引的方式读数据;或采取全读出的方式,一次全读出所有列,具体文件配置如下:
|
<?xml version="1.0" encoding="UTF-8" ?> <dataConfig> <dataSource name="mysqlServer" type="JdbcDataSource" driver="com.mysql.jdbc.Driver" batchSize="-1" url="jdbc:mysql://192.103.101.110:3306/locationplatform" user="lpuser" password="jlitpassok"/> <document> <entity name="locatedentity" pk="id" query="select id,time from locationplatform.locatedentity where isdelete=0 and my_date > '${dataimporter.last_index_time}'" deletedPkQuery="select id from locationplatform.locatedentity where isdelete=1 and my_date > '${dataimporter.last_index_time}'" deltaQuery="select -1 id" deltaImportQuery="select id,time from locationplatform.locatedentity where isdelete=0 and my_date > '${dataimporter.last_index_time}'"> <field column="id" name="id"/> <field column="time" name="time"/> </entity> </document> </dataConfig> |
l 注意:作者不推荐使用DataImportHandler,有其它更好更方便的实现可以使用。
1.2 Solr创建索引效率
l ConcurrentUpdateSolrServer使用http方式,embedded方式官方不推荐使用。ConcurrentUpdateSolrServer不需要commit,solrServer.add(doc)即可添加数据。SolrServer solrServer = newConcurrentUpdateSolrServer(solrUrl, 队列大小, 线程数)其需要与autoCommit、autoSoftCommit配置搭配使用,网上建议配置如下:|
<autoCommit> <maxTime>100000(1-10min)</maxTime> <openSearcher>false</openSearcher> </autoCommit> <autoSoftCommit> <maxTime>1000(1s)</maxTime> </autoSoftCommit> |
如需具体的测试代码可以联系本人。
l 17个字段,四核CPU,16G内存,千兆网络
| 数据量(W条) | 线程数 | 队列大小 | 时间(s) | 网络(MB/s) | 速率(W条/s) |
| 200 | 20 | 10000 | 88 | 10.0 | 2.27 |
| 200 | 20 | 20000 | 133 | 9.0 | 1.50 |
| 200 | 40 | 10000 | 163 | 10.0 | 1.22 |
| 200 | 50 | 10000 | 113 | 10.5 | 1.76 |
| 200 | 100 | 10000 | 120 | 10.5 | 1.67 |
l NRTCachingDirectory速度偏慢,会在某一时间索引添加停滞,Size先大后小,减小后索引添加继续。
l 大小:1亿索引大小约为13-16GB,2亿索引大小约为30GB。
1.3 Solr搜索方式
l 交集:{name:亿度 AND address:海淀} {text:海淀 AND 亿度}。l 联集:{name:亿度 OR address:海淀} {text:海淀 OR 亿度}。
l 排除:{text:海淀 -亿度}。
l 通配符:{bank:中国*银}。
l 范围:{num:[30 TO60]}。
l 分页:start rows
l 排序:sort
l Group 权重中文分词 ...
1.4 亿级数据搜索速度
l 本节测试是基于1.2节创建的索引上的。l精确搜索
| 数据量(亿条) | 字段数 | 字段类型 | 时间(ms) |
| 1 | 1 | long | 1 |
| 1 | 1 | double | 80-1400 |
| 1 | 1 | string | 7-800 |
| 1 | 1 | date | 2-400 |
| 1 | 2(OR) | long | 2 |
| 1 | 2(OR) | double | 200-2400 |
| 1 | 2(OR) | string | 500-1000 |
| 1 | 2(OR) | date | 5-500 |
| 数据量(亿条) | 字段数 | 字段类型 | 时间(ms) |
| 1 | 1 | long | 2000-10000 |
| 1 | 1 | double | 1000-17000 |
| 1 | 1 | string | 20-16000 |
| 1 | 1 | date | / |
| 1 | 2(OR) | long | 3000-25000 |
| 1 | 2(OR) | double | 7000-45000 |
| 1 | 2(OR) | string | 3000-48000 |
| 1 | 2(OR) | date | / |
| 数据量(亿条) | 字段数 | 字段类型 | 时间(ms) |
| 1 | 1 | long | 6-46000 |
| 1 | 1 | double | 80-11000 |
| 1 | 1 | string | 7-3000 |
| 1 | 1 | date | 1000-2000 |
| 1 | 2(OR) | long | 100-13000 |
| 1 | 2(OR) | double | 100-60000 |
| 1 | 2(OR) | string | 3000-13000 |
| 1 | 2(OR) | date | 7000-10000 |
范围越大,结果数据越多,搜索花费时间越长。
第一次搜索较慢,后来时间花费较少。
如对本文有疑问,请提交到交流论坛,广大热心网友会为你解答!! 点击进入论坛

