网站架构模式在新浪微博的应用
架构模式在新浪微博的应用
短短几年时间新浪微博的用户数就从零增长到数亿,明星用户的粉丝数达数千万,围绕着新浪微博正在发展一个集社交、媒体、游戏、电商等多位一体的生态系统。
同大多数网站一样,新浪微博也是从一个小网站发展起来的。简单的LAMP(Linux+Apache+MySQL+PHP)架构,支撑起最初的新浪微博,应用程序用PHP开发,所有的数据,包括微博、用户、关系都存储在MySQL数据库中。
这样简单的架构无法支撑新浪微博快速发展的业务需求,随着访问用户的逐渐增加,系统不堪重负。新浪微博的架构在较短时间内几经重构,最后形成现在的架构,如图2.1所示。
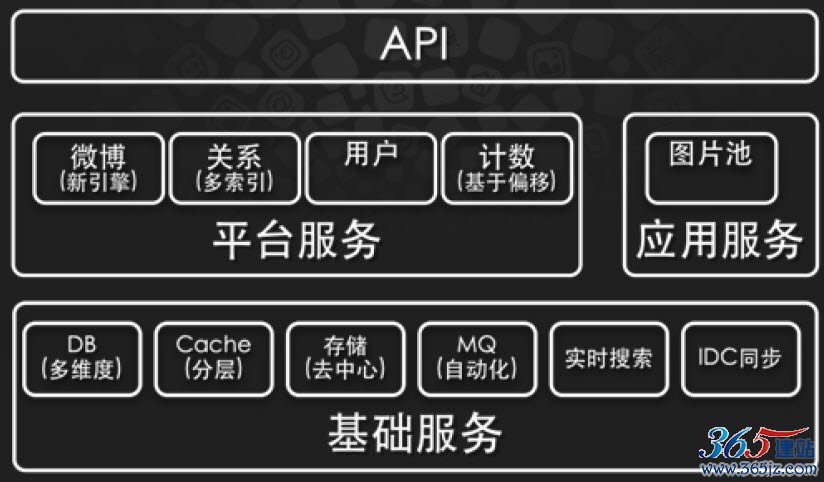
图2.1 新浪微博的系统架构
系统分为三个层次,最下层是基础服务层,提供数据库、缓存、存储、搜索等数据服务,以及其他一些基础技术服务,这些服务支撑了新浪微博的海量数据和高并发访问,是整个系统的技术基础。
中间层是平台服务和应用服务层,新浪微博的核心服务是微博、关系和用户,它们是新浪微博业务大厦的支柱。这些服务被分割为独立的服务模块,通过依赖调用和共享基础数据构成新浪微博的业务基础。
最上层是API和新浪微博的业务层,各种客户端(包括Web网站)和第三方应用,通过调用API集成到新浪微博的系统中,共同组成一个生态系统。
这些被分层和分割后的业务模块与基础技术模块分布式部署,每个模块都部署在一组独立的服务器集群上,通过远程调用的方式进行依赖访问。新浪微博在早期还使用过一种叫作MPSS(MultiPort Single Server,单服务器多端口)的分布式集群部署方案,在集群中的多台服务器上,每台都部署多个服务,每个服务使用不同的端口对外提供服务,通过这种方式使得有限的服务器可以部署更多的服务实例,改善服务的负载均衡和可用性。现在网站应用中常见的将物理机虚拟化成多个虚拟机后,在虚拟机上部署应用的方案跟新浪微博的MPSS方案异曲同工,只是更加简单,还能在不同虚拟机上使用相同的端口号。
在新浪微博的早期架构中,微博发布使用同步推模式,用户发表微博后系统会立即将这条微博插入到数据库所有粉丝的订阅列表中,
当用户量比较大时,特别是明星用户发布微博时,会引起大量的数据库写操作,超出数据库负载,系统性能急剧下降,用户响应延迟加剧。
后来新浪微博改用异步推拉结合的模式,用户发表微博后系统将微博写入消息队列后立即返回,用户响应迅速,消息队列消费者任务将微博推送给所有当前在线粉丝的订阅列表中,非在线用户登录后再根据关注列表拉取微博订阅列表。
由于微博频繁刷新,新浪微博使用多级缓存策略,热门微博和明星用户的微博缓存在所有的微博服务器上,在线用户的微博和近期微博缓存在分布式缓存集群中,对于微博操作中最常见的“刷微博”操作,几乎全部都是缓存访问操作,可以获得很好的系统性能。
为了提高系统的整体可用性和性能,新浪微博启用了多个数据中心。这些数据中心既是地区用户访问中心,用户可以就近访问最近的数据中心以加快访问速度,改善系统性能;同时也是数据冗余复制的灾备中心,所有的用户和微博数据通过远程消息系统在不同的数据中心之间同步,提高系统可用性。
同时,新浪微博还开发了一系列自动化工具,包括自动化监控,自动化发布,自动化故障修复等,这些自动化工具还在持续开发中,以改善运维水平提高系统可用性。
由于微博的开放特性,新浪微博也遇到了一系列的安全挑战,垃圾内容、僵尸粉、微博攻击从未停止,除了使用一般网站常见的安全策略,新浪微博在开放平台上使用多级安全审核的策略以保护系统和用户。
小结
在程序设计与架构设计领域,模式正变得越来越受人关注,许多人寄希望通过模式一劳永逸地解决自己的问题。正确使用模式可以更好地利用业界和前人的思想与实践,用更少的时间开发出更好的系统,使设计者的水平也达到更高的境界。但是模式受其适用场景限制,对系统的要求和约束也很多,不恰当地使用模式只会画虎不成反类犬,不但没有解决原来的老问题,反而带来了更棘手的新问题。
好的设计绝对不是模仿,不是生搬硬套某个模式,而是对问题深刻理解之上的创造与创新,即使是“微创新”,也是让人耳目一新的似曾相识。山寨与创新的最大区别不在于是否抄袭,是否模仿,而在于对问题和需求是否真正理解与把握。
如对本文有疑问,请提交到交流论坛,广大热心网友会为你解答!! 点击进入论坛
- 上一篇:大型网站架构模式
- 下一篇:Eclipse和PyCharm编辑器的安装教程图解

