网站的伸缩性架构设计(负载均衡/分布式缓存/数据存储服务器集群)
网站的伸缩性架构
所谓网站的伸缩性是指不需要改变网站的软硬件设计,仅仅通过改变部署的服务器数量就可以扩大或者缩小网站的服务处理能力。
京东网(www.360buy.com)在2011年年末的图书促销活动中,由于优惠幅度大引得大量买家访问,结果导致网站服务不可用,大部分用户在提交订单后,页面显示“Service is too busy”。当天晚上,京东网老板刘强东在微博发布消息称,已购买多台服务器以增加交易处理能力,第二天继续促销一天。结果第二天,用户在提交订单后,页面继续是“Service is too busy”。显然京东网当时的系统伸缩能力较弱,特别是订单处理子系统几乎没有什么伸缩能力。
与这些缺乏伸缩能力、关键时候掉链子的案例相对应的是淘宝网2012年“双十一”的促销活动,在活动开始的第一分钟,即有1000万独立用户访问网站,当天成功交易的订单总额达191亿,虽然淘宝网及支付宝网站出现了一些问题,但系统总体可用,绝大部分交易顺利完成。
大型网站的“大型”,在用户层面可以理解为大量用户及大量访问,如Facebook有超过10亿用户;在功能方面可以理解为功能庞杂、产品众多,如腾讯有超过1600种产品;在技术层面可以理解为网站需要部署大量的服务器,如Google大约有近100万台服务器。
本书开篇曾经讨论过,大型网站不是一开始就是大型网站的,而是从小型网站逐步演化而来的,Google诞生的时候也才只有一台服务器。设计一个大型网站或者一个大型软件系统,和将一个小网站逐渐演化成一个大型网站,其技术方案是完全不同的。前者如传统的银行系统,在设计之初就决定了系统的规模,如要服务的用户数、要处理的交易数等,然后采购大型计算机等昂贵的设备,将软件系统部署在上面,即成为一个大型系统,有朝一日这个大型系统也不能满足需求了,就花更多的钱打造一个更大型的系统。而网站一开始不可能规划出自己的规模,也不可能有那么多钱去开发一个大型系统,更不可能到了某个阶段再重新打造一个系统,只能摸着石头过河,从一台廉价的PC服务器开始自己的大型系统演化之路。
在这个渐进式的演化过程中,最重要的技术手段就是使用服务器集群,通过不断地向集群中添加服务器来增强整个集群的处理能力。
这就是网站系统的伸缩性架构,只要技术上能做到向集群中加入服务器的数量和集群的处理能力成线性关系,那么网站就可以以此手段不断提升自己的规模,从一个服务几十人的小网站发展成服务几十亿人的大网站,从只能存储几个G图片的小网站发展成存储几百P图片的大网站。
这个演化过程总体来说是渐进式的,而且总是在“伸”,也就是说,网站的规模和服务器的规模总是在不断扩大(通常,一个需要“缩”的网站可能已经无法经营下去了)。但是这个过程也可能因为运营上的需要而出现脉冲,比如前面案例中提到的电商网站的促销活动:在某个短时间内,网站的访问量和交易规模突然爆发式增长,然后又回归正常状态。这时就需要网站的技术架构具有极好的伸缩性——活动期间向服务器集群中加入更多服务器(及向网络服务商租借更多的网络带宽)以满足用户访问,活动结束后又将这些服务器下线以节约成本。
国内有许多传统企业“触网”,将传统业务搬上互联网,这是一件值得称道的事,传统行业与互联网结合将会创造出新的经济模式,改善人们的生活。但遗憾的是,有些传统企业将自己的管理模式和经营理念也照搬到互联网领域——在技术方面的表现就是一开始就企图打造一个大型网站。
网站架构的伸缩性设计
回顾网站架构发展历程,网站架构发展史就是一部不断向网站添加服务器的历史。只要工程师能向网站的服务器集群中添加新的机器,只要新添加的服务器能线性提高网站的整体服务处理能力,网站就无需为不断增长的用户和访问而焦虑。
一般说来,网站的伸缩性设计可分成两类,一类是根据功能进行物理分离实现伸缩,一类是单一功能通过集群实现伸缩。前者是不同的服务器部署不同的服务,提供不同的功能;后者是集群内的多台服务器部署相同的服务,提供相同的功能。
6.1.1 不同功能进行物理分离实现伸缩
网站发展早期——通过增加服务器提高网站处理能力时,新增服务器总是从现有服务器中分离出部分功能和服务,如图6.1所示。
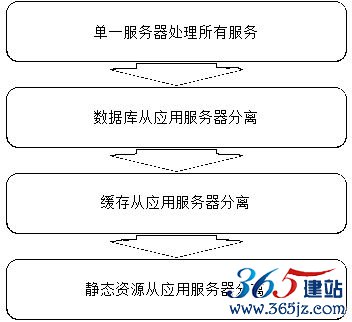
图6.1 通过物理分离实现服务器伸缩
每次分离都会有更多的服务器加入网站,使用新增的服务器处理某种特定服务。事实上,通过物理上分离不同的网站功能,实现网站伸缩性的手段,不仅可以用在网站发展早期,而且可以在网站发展的任何阶段使用。具体又可分成如下两种情况。
纵向分离(分层后分离):将业务处理流程上的不同部分分离部署,实现系统伸缩性,如图6.2所示。

图6.2 通过纵向分离部署实现系统伸缩性
横向分离(业务分割后分离):将不同的业务模块分离部署,实现系统伸缩性,如图6.3所示。

图6.3 通过横向分离部署实现系统伸缩性
横向分离的粒度可以非常小,甚至可以一个关键网页部署一个独立服务,比如对于电商网站非常重要的产品详情页面,商铺页面,搜索列表页面,每个页面都可以独立部署,专门维护。
6.1.2 单一功能通过集群规模实现伸缩
将不同功能分离部署可以实现一定程度的伸缩性,但是随着网站访问量的逐步增加,即使分离到最小粒度的独立部署,单一的服务器也不能满足业务规模的要求。因此必须使用服务器集群,即将相同服务部署在多台服务器上构成一个集群整体对外提供服务。
当一头牛拉不动车的时候,不要去寻找一头更强壮的牛,而是用两头牛来拉车。
以搜索服务器为例,如果一台服务器可以提供每秒1000次的请求服务,即QPS(Query Per Second)为1000。那么如果网站高峰时每秒搜索访问量为10000,就需要部署10台服务器构成一个集群。若以缓存服务器为例,如果每台服务器可缓存40GB数据,那么要缓存
100GB数据,就需要部署3台服务器构成一个集群。当然这些例子的计算都是简化的,事实上,计算一个服务的集群规模,需要同时考虑其对可用性、性能的影响及关联服务集群的影响。
具体来说,集群伸缩性又可分为应用服务器集群伸缩性和数据服务器集群伸缩性。这两种集群由于对数据状态管理的不同,技术实现也有非常大的区别。而数据服务器集群也可分为缓存数据服务器集群和存储数据服务器集群,这两种集群的伸缩性设计也不大相同。
6.2 应用服务器集群的伸缩性设计
我们在本书第5章提到,应用服务器应该设计成无状态的,即应用服务器不存储请求上下文信息,如果将部署有相同应用的服务器组成一个集群,每次用户请求都可以发送到集群中任意一台服务器上去处理,任何一台服务器的处理结果都是相同的。这样只要能将用户请求按照某种规则分发到集群的不同服务器上,就可以构成一个应用服务器集群,每个用户的每个请求都可能落在不同的服务器上。如图6.4所示。
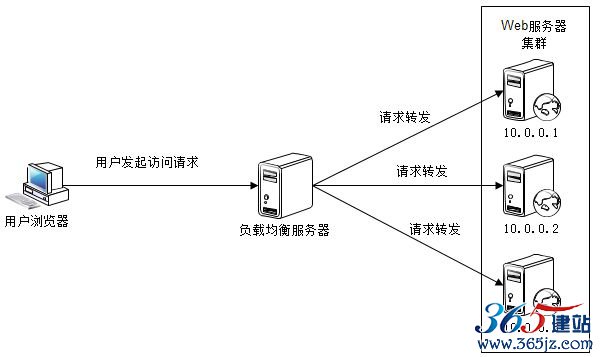
图6.4 负载均衡实现应用服务器伸缩性
如果HTTP请求分发装置可以感知或者可以配置集群的服务器数量,可以及时发现集群中新上线或下线的服务器,并能向新上线的服务器分发请求,停止向已下线的服务器分发请求,那么就实现了应用服务器集群的伸缩性。
这里,这个HTTP请求分发装置被称作负载均衡服务器。
负载均衡是网站必不可少的基础技术手段,不但可以实现网站的伸缩性,同时还改善网站的可用性,可谓网站的杀手锏之一。具体的技术实现也多种多样,从硬件实现到软件实现,从商业产品到开源软件,应有尽有,但是实现负载均衡的基础技术不外以下几种。
6.2.1 HTTP重定向负载均衡
利用HTTP重定向协议实现负载均衡。如图6.5所示。
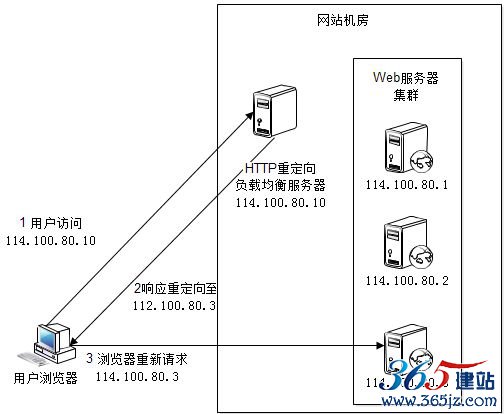
图6.5 HTTP重定向负载均衡原理
HTTP重定向服务器是一台普通的应用服务器,其唯一的功能就是根据用户的HTTP请求计算一台真实的Web服务器地址,并将该
Web服务器地址写入HTTP重定向响应中(响应状态码302)返回给用户浏览器。在图6.5中,浏览器请求访问域名www.mysite.com,DNS服务器解析得到IP地址是114.100.80.10,即HTTP重定向服务器的IP地址。然后浏览器通过IP地址 114.100.80.10访问HTTP重定向负载均衡服务器后,服务器根据某种负载均衡算法计算获得一台实际物理服务器的地址(114.100.80.3),构造一个包含该实际物理服务器地址的重定向响应返回给浏览器,浏览器自动重新请求实际物理服务器的IP地址114.100.80.3,完成访问。
这种负载均衡方案的优点是比较简单。缺点是浏览器需要两次请求服务器才能完成一次访问,性能较差;重定向服务器自身的处理能力有可能成为瓶颈,整个集群的伸缩性规模有限;使用HTTP302响应码重定向,有可能使搜索引擎判断为SEO作弊,降低搜索排名。因此实践中使用这种方案进行负载均衡的案例并不多见。
6.2.2 DNS域名解析负载均衡
这是利用DNS处理域名解析请求的同时进行负载均衡处理的一种方案,如图6.6所示。
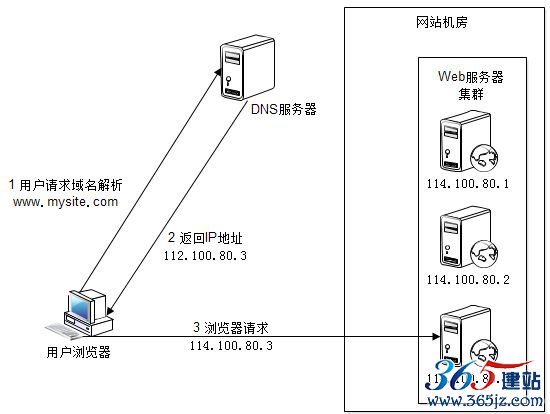
图6.6 DNS域名解析负载均衡原理
在DNS服务器中配置多个A记录,如:www.mysite.com IN A 114.100.80.1、www.mysite.com IN A 114.100.80.2、www.mysite.com IN A 114.100.80.3。
每次域名解析请求都会根据负载均衡算法计算一个不同的IP地址返回,这样A记录中配置的多个服务器就构成一个集群,并可以实现负载均衡。图6.6中的浏览器请求解析域名www.mysite.com,DNS根据A记录和负载均衡算法计算得到一个IP地址114.100.80.3,并返回给浏览器;浏览器根据该IP地址,访问真实物理服务器114.100.80.3。
DNS域名解析负载均衡的优点是将负载均衡的工作转交给DNS,省掉了网站管理维护负载均衡服务器的麻烦,同时许多DNS还支持基于地理位置的域名解析,即会将域名解析成距离用户地理最近的一个服务器地址,这样可加快用户访问速度,改善性能。但是DNS域名解析负载均衡也有缺点,就是目前的DNS是多级解析,每一级DNS都可能缓存A记录,当下线某台服务器后,即使修改了DNS的A记录,要使其生效也需要较长时间,这段时间,DNS依然会将域名解析到已经下线的服务器,导致用户访问失败;而且DNS负载均衡的控制权在域名服务商那里,网站无法对其做更多改善和更强大的管理。
事实上,大型网站总是部分使用DNS域名解析,利用域名解析作为第一级负载均衡手段,即域名解析得到的一组服务器并不是实际提供Web服务的物理服务器,而是同样提供负载均衡服务的内部服务器,这组内部负载均衡服务器再进行负载均衡,将请求分发到真实的Web服务器上。
6.2.3 反向代理负载均衡
利用反向代理服务器进行负载均衡,如图6.7所示。
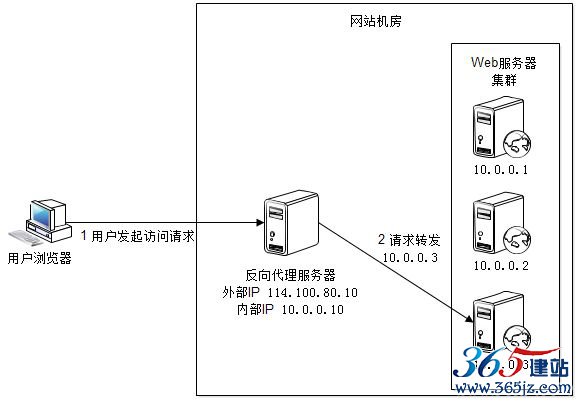
图6.7 反向代理负载均衡原理
前面我们提到利用反向代理缓存资源,以改善网站性能。实际上,在部署位置上,反向代理服务器处于Web服务器前面(这样才可能缓存Web响应,加速访问),这个位置也正好是负载均衡服务器的位置,所以大多数反向代理服务器同时提供负载均衡的功能,管理一组Web服务器,将请求根据负载均衡算法转发到不同Web服务器上。Web服务器处理完成的响应也需要通过反向代理服务器返回给用户。由于Web服务器不直接对外提供访问,因此Web服务器不需要使用外部IP地址,而反向代理服务器则需要配置双网卡和内部外部两套IP地址。
图6.7中,浏览器访问请求的地址是反向代理服务器的地址114.100.80.10,反向代理服务器收到请求后,根据负载均衡算法计算得到一台真实Web服务器10.0.0.1,然后将数据目的IP地址修改为10.0.0.1,不需要通过用户进程处理。真实Web应用服务器处理完成后,响应数据包回到负载均衡服务器,负载均衡服务器再将数据包源地址修改为自身的IP地址(114.100.80.10)发送给用户浏览器。
这里的关键在于真实物理Web服务器响应数据包如何返回给负载均衡服务器。一种方案是负载均衡服务器在修改目的IP地址的同时修改源地址,将数据包源地址设为自身IP,即源地址转换(SNAT),这样Web服务器的响应会再回到负载均衡服务器;另一种方案是将负载均衡服务器同时作为真实物理服务器集群的网关服务器,这样所有响应数据都会到达负载均衡服务器。
IP负载均衡在内核进程完成数据分发,较反向代理负载均衡(在应用程序中分发数据)有更好的处理性能。但是由于所有请求响应都需要经过负载均衡服务器,集群的最大响应数据吞吐量不得不受制于负载均衡服务器网卡带宽。对于提供下载服务或者视频服务等需要传输大量数据的网站而言,难以满足需求。能不能让负载均衡服务器只分发请求,而使响应数据从真实物理服务器直接返回给用户呢?
6.2.5 数据链路层负载均衡
顾名思义,数据链路层负载均衡是指在通信协议的数据链路层修改mac地址进行负载均衡,如图6.9所示。
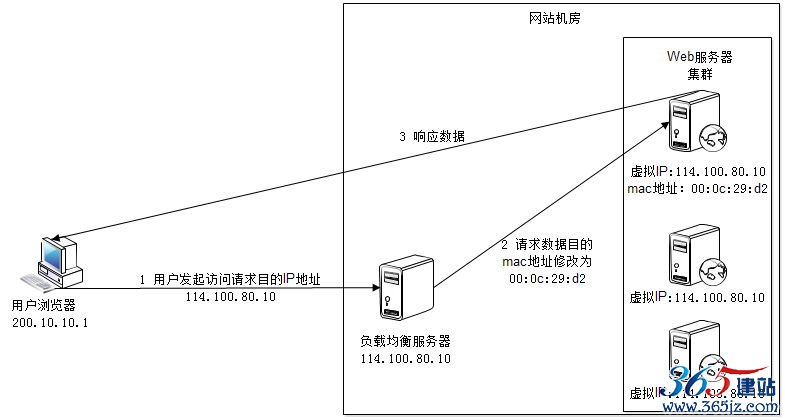
图6.9 数据链路层负载均衡原理
这种数据传输方式又称作三角传输模式,负载均衡数据分发过程中不修改IP地址,只修改目的mac地址,通过配置真实物理服务器集群所有机器虚拟IP和负载均衡服务器IP地址一致,从而达到不修改数据包的源地址和目的地址就可以进行数据分发的目的,由于实际处理请求的真实物理服务器IP和数据请求目的IP一致,不需要通过负载均衡服务器进行地址转换,可将响应数据包直接返回给用户浏览器,避免负载均衡服务器网卡带宽成为瓶颈。这种负载均衡方式又称作直接路由方式(DR)。
在图6.9中,用户请求到达负载均衡服务器114.100.80.10后,负载均衡服务器将请求数据的目的mac地址修改为00:0c:29:d2,并不修改数目包目标IP地址,由于Web服务器集群所有服务器的虚拟IP地址都和负载均服务器的IP地址相同,因此数据可以正常传输到达mac地址00:0c:29:d2对应的服务器,该服务器处理完成后发送响应数据到网站的网关服务器,网关服务器直接将该数据包发送到用户浏览器(通过互联网),响应数据不需要通过负载均衡服务器。
使用三角传输模式的链路层负载均衡是目前大型网站使用最广的一种负载均衡手段。在Linux平台上最好的链路层负载均衡开源产品是LVS(Linux Virtual Server)。
6.2.6 负载均衡算法
负载均衡服务器的实现可以分成两个部分:
1.根据负载均衡算法和Web服务器列表计算得到集群中一台Web服务器的地址。
2.将请求数据发送到该地址对应的Web服务器上。
前面描述了如何将请求数据发送到Web服务器,而具体的负载均衡算法通常有以下几种。
轮询(Round Robin,RR)
所有请求被依次分发到每台应用服务器上,即每台服务器需要处理的请求数目都相同,适合于所有服务器硬件都相同的场景。
加权轮询(Weighted Round Robin,WRR)
根据应用服务器硬件性能的情况,在轮询的基础上,按照配置的权重将请求分发到每个服务器,高性能的服务器能分配更多请求。
随机(Random)
请求被随机分配到各个应用服务器,在许多场合下,这种方案都很简单实用,因为好的随机数本身就很均衡。
6.3 分布式缓存集群的伸缩性设计
我们在之前讨论过分布式缓存,不同于应用服务器集群的伸缩性设计,分布式缓存集群的伸缩性不能使用简单的负载均衡手段来实现。
和所有服务器都部署相同应用的应用服务器集群不同,分布式缓存服务器集群中不同服务器中缓存的数据各不相同,缓存访问请求不可以在缓存服务器集群中的任意一台处理,必须先找到缓存有需要数据的服务器,然后才能访问。这个特点会严重制约分布式缓存集群的伸缩性设计,因为新上线的缓存服务器没有缓存任何数据,而已下线的缓存服务器还缓存着网站的许多热点数据。
必须让新上线的缓存服务器对整个分布式缓存集群影响最小,也就是说新加入缓存服务器后应使整个缓存服务器集群中已经缓存的数据尽可能还被访问到,这是分布式缓存集群伸缩性设计的最主要目标。
6.3.1 Memcached分布式缓存集群的访问模型
以Memcached为代表的分布式缓存,访问模型如图6.10所示。
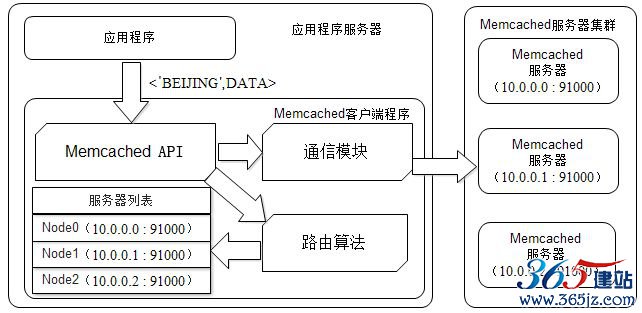
图6.10 Memcached分布式缓存访问模型
应用程序通过Memcached客户端访问Memcached服务器集群,
Memcached客户端主要由一组API、Memcached服务器集群路由算法、
Memcached服务器集群列表及通信模块构成。
其中路由算法负责根据应用程序输入的缓存数据KEY计算得到应该将数据写入到Memcached的哪台服务器(写缓存)或者应该从哪台服务器读数据(读缓存)。
一个典的型缓存写操作如图6.10中箭头所示路径。应用程序输入需要写缓存的数据路<'BEIJING',DATA>,API将KEY('BEIJING')输入路由算法模块,路由算法根据KEY和Memcached集群服务器列表计算得到一台服务编号(NODE1),进而得到该机器的IP地址和端口(10.0.0.0:91000)。API调用通信模块和编号为NODE1的服务器通信,将数据的<'BEIJING',DATA>写入该服务器。完成一次分布式缓存的写操作。
读缓存的过程和写缓存一样,由于使用同样的路由算法和服务器列表,只要应用程序提供相同的KEY('BEIJING'),Memcached客户端总是访问相同的服务器(NODE1)去读取数据。只要服务器还缓存着该数据,就能保证缓存命中。
6.3.2 Memcached分布式缓存集群的伸缩性挑战
由上述讨论可得知,在Memcached分布式缓存系统中,对于服务器集群的管理,路由算法至关重要,和负载均衡算法一样,决定着究竟该访问集群中的哪台服务器。
简单的路由算法可以使用余数Hash:用服务器数目除以缓存数据KEY的Hash值,余数为服务器列表下标编号。假设图6.10中'BEIJING'的Hash值是490806430(Java中的HashCode()返回值),用服务器数目3除以该值,得到余数1,对应节点NODE1。由于HashCode具有随机性,因此使用余数Hash路由算法可保证缓存数据在整个Memcached服务器集群中比较均衡地分布。
对余数Hash路由算法稍加改进,就可以实现和负载均衡算法中加权负载均衡一样的加权路由。事实上,如果不需要考虑缓存服务器集群伸缩性,余数Hash几乎可以满足绝大多数的缓存路由需求。
但是,当分布式缓存集群需要扩容的时候,事情就变得棘手了。
假设由于业务发展,网站需要将3台缓存服务器扩容至4台。更改服务器列表,仍旧使用余数Hash,用4除以'BEIJING'的Hash值49080643,余数为2,对应服务器NODE2。由于数据。
<'BEIJING',DATA>缓存在NODE1,对NODE2的读缓存操作失败,缓存没有命中。
很容易就可以计算出,3台服务器扩容至4台服务器,大约有75%(3/4)被缓存了的数据不能正确命中,随着服务器集群规模的增大,这个比例线性上升。当100台服务器的集群中加入一台新服务器,不能命中的概率是99%(N/(N+1))。
这个结果显然是不能接受的,在网站业务中,大部分的业务数据读操作请求事实上是通过缓存获取的,只有少量读操作请求会访问数据库,因此数据库的负载能力是以有缓存为前提而设计的。当大部分被缓存了的数据因为服务器扩容而不能正确读取时,这些数据访问的压力就落到了数据库的身上,这将大大超过数据库的负载能力,严重的可能会导致数据库宕机(这种情况下,不能简单重启数据库,网站也需要较长时间才能逐渐恢复正常。)
本来加入新的缓存服务器是为了降低数据库的负载压力,但是操作不当却导致了数据库的崩溃。如果不对问题和解决方案有透彻了解,网站技术总有想不到的陷阱让架构师一脚踩空。遇到这种情况,用某网站一位资深架构师的话说,就是“一股寒气从脚底板窜到了脑门心”。
一种解决办法是在网站访问量最少的时候扩容缓存服务器集群,这时候对数据库的负载冲击最小。然后通过模拟请求的方法逐渐预热缓存,使缓存服务器中的数据重新分布。但是这种方案对业务场景有要求,还需要技术团队通宵加班(网站访问低谷通常是在半夜)。
能不能通过改进路由算法,使得新加入的服务器不影响大部分缓存数据的正确命中呢?目前比较流行的算法是一致性Hash算法。
6.3.3 分布式缓存的一致性Hash算法
一致性Hash算法通过一个叫作一致性Hash环的数据结构实现
KEY到缓存服务器的Hash映射,如图6.11所示。
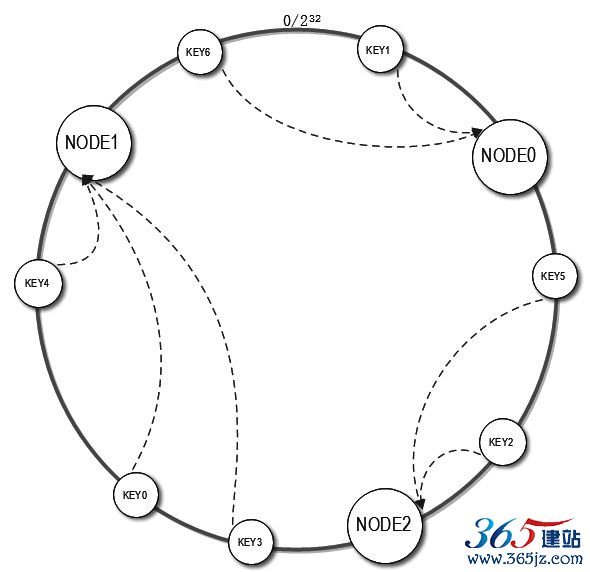
图6.11 一致性Hash算法原理
具体算法过程为:先构造一个长度为0~2^32(2的32次幂)的整数环(这个环被称作一致性Hash环),根据节点名称的Hash值(其分布范围同样为0~2^32(2的32次幂))将缓存服务器节点放置在这个Hash环上。然后根据需要缓存的数据的KEY值计算得到其Hash值(其分布范围也同样为0~2^32(2的32次幂)),然后在Hash环上顺时针查找距离这个KEY的Hash值最近的缓存服务器节点,完成KEY到服务器的Hash映射查找。
在图6.11中,假设NODE1的Hash值为3,594,963,423,NODE2的Hash值为1,845,328,979,而KEY0的Hash值为2,534,256,785,那么KEY0在环上顺时针查找,找到的最近的节点就是NODE1。
当缓存服务器集群需要扩容的时候,只需要将新加入的节点名称(NODE3)的Hash值放入一致性Hash环中,由于KEY是顺时针查找距离其最近的节点,因此新加入的节点只影响整个环中的一小段,如图6.12中深色一段。
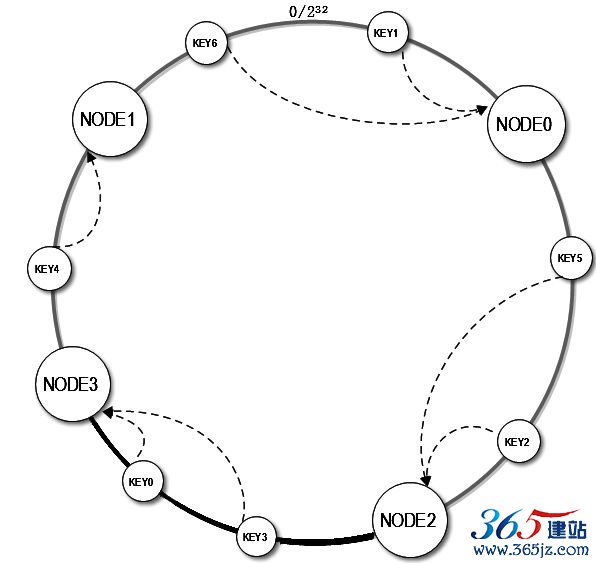
图6.12 增加节点后的一致性Hash环结构
假设NODE3的Hash值是2,790,324,235,那么加入NODE3后,
KEY0(Hash值2,534,256,785)顺时针查找得到的节点就是NODE3。
图6.12中,加入新节点NODE3后,原来的KEY大部分还能继续计算到原来的节点,只有KEY3、KEY0从原来的NODE1重新计算到NODE3。这样就能保证大部分被缓存的数据还可以继续命中。3台服
务器扩容至4台服务器,可以继续命中原有缓存数据的概率是75%,远高于余数Hash的25%,而且随着集群规模越大,继续命中原有缓存数据的概率也逐渐增大,100台服务器扩容增加1台服务器,继续命中的概率是99%。虽然仍有小部分数据缓存在服务器中不能被读到,但是这个比例足够小,通过访问数据库获取也不会对数据库造成致命的负载压力。
具体应用中,这个长度为2的一致性Hash环通常使用二叉查找树实现,Hash查找过程实际上是在二叉查找树中查找不小于查找数的最小数值。当然这个二叉树的最右边叶子节点和最左边的叶子节点相连接,构成环。
但是,上面描述的算法过程还存在一个小小的问题。
新加入的节点NODE3只影响了原来的节点NODE1,也就是说一部分原来需要访问NODE1的缓存数据现在需要访问NODE3(概率上是50%)。但是原来的节点NODE0和NODE2不受影响,这就意味着
NODE0和NODE2缓存数据量和负载压力是NODE1与NODE3的两倍。如果4台机器的性能是一样的,那么这种结果显然不是我们需要的。
怎么办?
计算机领域有句话:计算机的任何问题都可以通过增加一个虚拟层来解决。计算机硬件、计算机网络、计算机软件都莫不如此。计算机网络的7层协议,每一层都可以看作是下一层的虚拟层;计算机操作系统可以看作是计算机硬件的虚拟层;Java虚拟机可以看作是操作系统的虚拟层;分层的计算机软件架构事实上也是利用虚拟层的概念。
解决上述一致性Hash算法带来的负载不均衡问题,也可以通过使用虚拟层的手段:将每台物理缓存服务器虚拟为一组虚拟缓存服务器,将虚拟服务器的Hash值放置在Hash环上,KEY在环上先找到虚拟服务器节点,再得到物理服务器的信息。
这样新加入物理服务器节点时,是将一组虚拟节点加入环中,如果虚拟节点的数目足够多,这组虚拟节点将会影响同样多数目的已经在环上存在的虚拟节点,这些已经存在的虚拟节点又对应不同的物理节点。最终的结果是:新加入一台缓存服务器,将会较为均匀地影响原来集群中已经存在的所有服务器,也就是说分摊原有缓存服务器集群中所有服务器的一小部分负载,其总的影响范围和上面讨论过的相同。如图6.13所示。
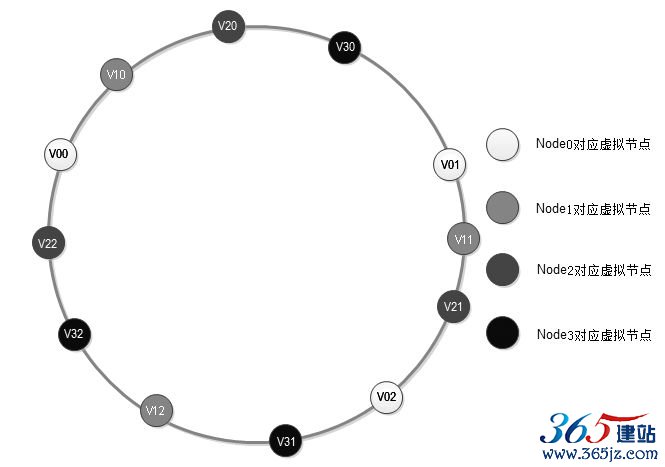
图6.13 使用虚拟节点的一致性Hash环
在图6.13中,新加入节点NODE3对应的一组虚拟节点为V30,V31,V32,加入到一致性Hash环上后,影响V01,V12,V22三个虚拟节点,而这三个虚拟节点分别对应NODE0,NODE1,NODE2三个物理节点。最终Memcached集群中加入一个节点,但是同时影响到集群中已存在的三个物理节点,在理想情况下,每个物理节点受影响的数据量(还在缓存中,但是不能被访问到数据)为其节点缓存数据量的1/4(X/(N+X),N为原有物理节点数,X为新加入物理节点数),也就是集群中已经被缓存的数据有75%可以被继续命中,和未使用虚拟节点的一致性Hash算法结果相同。
显然每个物理节点对应的虚拟节点越多,各个物理节点之间的负载越均衡,新加入物理服务器对原有的物理服务器的影响越保持一致(这就是一致性Hash这个名称的由来)。那么在实践中,一台物理服务器虚拟为多少个虚拟服务器节点合适呢?太多会影响性能,太少又会导致负载不均衡,一般说来,经验值是150,当然根据集群规模和负载均衡的精度需求,这个值应该根据具体情况具体对待。
6.4 数据存储服务器集群的伸缩性设计
和缓存服务器集群的伸缩性设计不同,数据存储服务器集群的伸缩性对数据的持久性和可用性提出了更高的要求。
缓存的目的是加速数据读取的速度并减轻数据存储服务器的负载压力,因此部分缓存数据的丢失不影响业务的正常处理,因为数据还可以从数据库等存储服务器上获取。
而数据存储服务器必须保证数据的可靠存储,任何情况下都必须保证数据的可用性和正确性。因此缓存服务器集群的伸缩性架构方案不能直接适用于数据库等存储服务器。存储服务器集群的伸缩性设计相对更复杂一些,具体说来,又可分为关系数据库集群的伸缩性设计和NoSQL数据库的伸缩性设计。
6.4.1 关系数据库集群的伸缩性设计
关系数据库凭借其简单强大的SQL和众多成熟的商业数据库产品,占据了从企业应用到网站系统的大部分业务数据存储服务。市场上主要的关系数据都支持数据复制功能,使用这个功能可以对数据库进行简单伸缩。图6.14为使用数据复制的MySQL集群伸缩性方案。
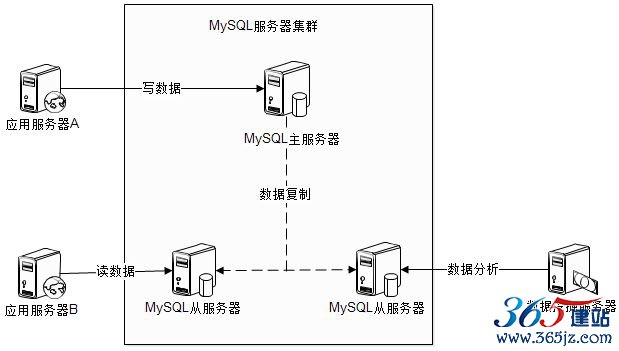
图6.14 MySQL集群伸缩性方案
在这种架构中,虽然多台服务器部署MySQL实例,但是它们的角色有主从之分,数据写操作都在主服务器上,由主服务器将数据同步到集群中其他从服务器,数据读操作及数据分析等离线操作在从服务器上进行。
除了数据库主从读写分离,前面提到的业务分割模式也可以用在数据库,不同业务数据表部署在不同的数据库集群上,即俗称的数据分库。这种方式的制约条件是跨库的表不能进行Join操作。
在大型网站的实际应用中,即使进行了分库和主从复制,对一些单表数据仍然很大的表,比如Facebook的用户数据库,淘宝的商品数据库,还需要进行分片,将一张表拆开分别存储在多个数据库中。
目前网站在线业务应用中比较成熟的支持数据分片的分布式关系数据库产品主要有开源的Amoeba(http://sourceforge.net/projects/
amoeba/)和Cobar(http://code.alibabatech.com/wiki/display/cobar/Home)。这两个产品有相似的架构设计,以Cobar为例,部署模型如图6.15所示。
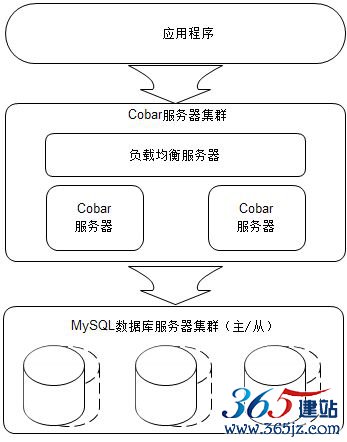
图6.15 Cobar部署模型
Cobar是一个分布式关系数据库访问代理,介于应用服务器和数据库服务器之间(Cobar也支持非独立部署,以lib的方式和应用程序部署在一起)。应用程序通过JDBC驱动访问Cobar集群,Cobar服务器根据SQL和分库规则分解SQL,分发到MySQL集群不同的数据库实例上执行(每个MySQL实例都部署为主/从结构,保证数据高可用)。
Cobar系统组件模型如图6.16所示。
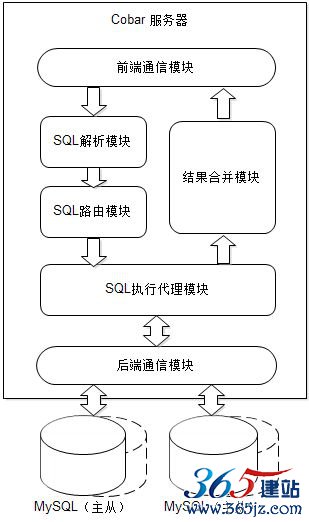
图6.16 Cobar系统组件模型
前端通信模块负责和应用程序通信,接收到SQL请求(select *
from users where userid in(12,22,23))后转交给SQL解析模块,
SQL解析模块解析获得SQL中的路由规则查询条件(useridin(12,22,23))再转交给SQL路由模块,SQL路由模块根据路由规则配置(userid为偶数路由至数据库A,userid为奇数路由至数据库B)将应用程序提交的SQL分解成两条SQL(select * from users where userid in(12,22);select * from users where userid in(23);)转交给SQL执行代理模块,发送至数据库A和数据库B分别执行。
数据库A和数据库B的执行结果返回至SQL执行模块,通过结果合并模块将两个返回结果集合并成一个结果集,最终返回给应用程序,完成在分布式数据库中的一次访问请求。
那么Cobar如何做集群的伸缩呢?
Cobar的伸缩有两种:Cobar服务器集群的伸缩和MySQL服务器集群的伸缩。
Cobar服务器可以看作是无状态的应用服务器,因此其集群伸缩可以简单使用负载均衡的手段实现。而MySQL中存储着数据,要想保证集群扩容后数据一致负载均衡,必须要做数据迁移,将集群中原来机器中的数据迁移到新添加的机器中,如图6.17所示。
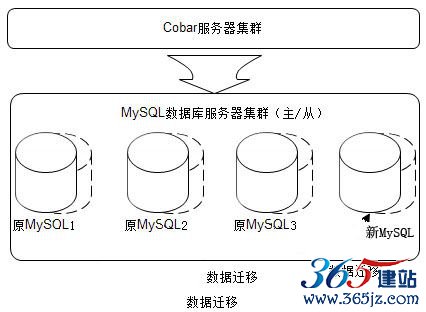
图6.17 Cobar集群伸缩原理
具体迁移哪些数据可以利用一致性Hash算法(即路由模块使用一致性Hash算法进行路由),尽量使需要迁移的数据最少。但是迁移数据需要遍历数据库中每条记录(的索引),重新进行路由计算确定其是否需要迁移,这会对数据库访问造成一定压力。并且需要解决迁移过程中数据的一致性、可访问性、迁移过程中服务器宕机时的可用性等诸多问题。
实践中,Cobar利用了MySQL的数据同步功能进行数据迁移。数据迁移不是以数据为单位,而是以Schema为单位。在Cobar集群初始化时,在每个MySQL实例创建多个Schema(根据业务远景规划未来集群规模,如集群最大规模为1000台数据库服务器,那么总的初始Schema数≥1000)。集群扩容的时候,从每个服务器中迁移部分Schema到新机器中,由于迁移以Schema为单位,迁移过程可以使用
MySQL的同步机制,如图6.18所示。
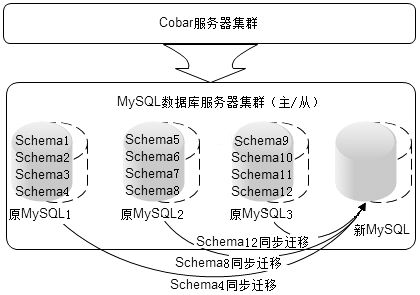
图6.18 利用MySQL同步机制实现Cobar集群伸缩
同步完成时,即新机器中Schema数据和原机器中Schema数据一致的时候,修改Cobar服务器的路由配置,将这些Schema的IP修改为新机器的IP,然后删除原机器中的相关Schema,完成MySQL集群扩容。
在整个分布式关系数据库的访问请求过程中,Cobar服务器处理消耗的时间是很少的,时间花费主要还是在MySQL数据库端,因此应用程序通过Cobar访问分布式关系数据库,性能基本和直接访问关系数据库相当,可以满足网站在线业务的实时处理需求。事实上由于
Cobar代替应用程序连接数据库,数据库只需要维护更少的连接,减少不必要的资源消耗,改善性能。
但由于Cobar路由后只能在单一数据库实例上处理查询请求,因此无法执行跨库的JOIN操作,当然更不能执行跨库的事务处理。
相比关系数据库本身功能上的优雅强大,目前各类分布式关系数据库解决方案都显得非常简陋,限制了关系数据库某些功能的使用。
但是当网站业务面临不停增长的海量业务数据存储压力时,又不得不利用分布式关系数据库的集群伸缩能力,这时就必须从业务上回避分布式关系数据库的各种缺点:避免事务或利用事务补偿机制代替数据库事务;分解数据访问逻辑避免JOIN操作等。
除了上面提到的分布式数据库,还有一类分布式数据库可以支持
JOIN操作执行复杂的SQL查询,如GreenPlum。但是这类数据库的访问延迟比较大(可以想象,JOIN操作需要在服务器间传输大量的数据),因此一般使用在数据仓库等非实时业务中。
6.4.2 NoSQL数据库的伸缩性设计
在计算机数据存储领域,一直是关系数据库(RelationDatabase)的天下,以至传统企业应用领域,许多应用系统设计都是面向数据库设计——先设计数据库然后设计程序,从而导致关系模型绑架对象模型,并由此引申出旷日持久的业务对象贫血模型与充血模型之争。业界为了解决关系数据库的不足,提出了诸多方案,比
较有名的是对象数据库,但是这些数据库的出现只是进一步证明关系数据库的优越而已。直到大型网站遇到了关系数据库难以克服的缺陷——糟糕的海量数据处理能力及僵硬的设计约束,局面才有所改善。为了解决上述问题,NoSQL这一概念被提了出来,以弥补关系数据库的不足。
NoSQL,主要指非关系的、分布式的数据库设计模式。也有许多专家将NoSQL解读为Not Only SQL,表示NoSQL只是关系数据库的补充,而不是替代方案。一般而言,NoSQL数据库产品都放弃了关系数据库的两大重要基础:以关系代数为基础的结构化查询语言(SQL)和事务一致性保证(ACID)。而强化其他一些大型网站更关注的特性:高可用性和可伸缩性。
开源社区有各种NoSQL产品,其支持的数据结构和伸缩特性也各不相同,目前看来,应用最广泛的是Apache HBase。
HBase为可伸缩海量数据储存而设计,实现面向在线业务的实时数据访问延迟。HBase的伸缩性主要依赖其可分裂的HRegion及可伸缩的分布式文件系统HDFS实现。
HBase的整体架构如图6.19所示。HBase中,数据以HRegion为单位进行管理,也就是说应用程序如果想要访问一个数据,必须先找到HRegion,然后将数据读写操作提交给HRegion,由HRegion完成存储层面的数据操作。每个HRegion中存储一段Key值区间
[key1,key2)的数据,HRegionServer是物理服务器,每个HRegionServer上可以启动多个HRegion实例。当一个HRegion中写入的数据太多,达到配置的阈值时,HRegion会分裂成两个HRegion,
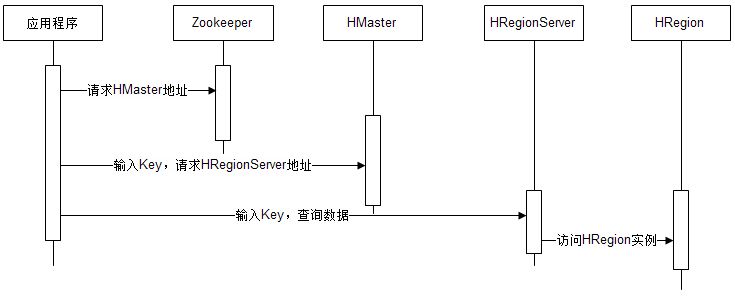
图6.20 HBase数据寻址过程时序图
数据写入过程也是一样,需要先得到HRegion才能继续操作,HRegion会把数据存储在若干个叫作HFile格式的文件中,这些文件使用HDFS分布式文件系统(参考本书第4章)存储,在整个集群内分布并高可用。当一个HRegion中数据量太多时,HRegion(连同HFile)会分裂成两个HRegion,并根据集群中服务器负载进行迁移,如果集群中有新加入的服务器,也就是说有了新的HRegionServer,由于其负载较低,也会把HRegion迁移过去并记录到HMaster,从而实现HBase的线性伸缩。
伸缩性架构设计能力是网站架构师必须具备的能力。
伸缩性架构设计是简单的,因为几乎所有稍有规模的网站都必须是可伸缩的,有很多案例可供借鉴,同时又有大量商业的、开源的提供伸缩性能力的软硬件产品可供选用。然而伸缩性设计又是复杂的,没有通用的、完美的解决方案和产品,网站伸缩性往往和可用性、正确性、性能等耦合在一起,改善伸缩性可能会影响一些网站的其他特性,网站架构师必须对网站的商业目标、历史演化、技术路线了然于胸,甚至还需要综合考虑技术团队的知识储备和结构、管理层的战略愿景和规划,才能最终做出对网站伸缩性架构最合适的决策。
一个具有良好伸缩性架构设计的网站,其设计总是走在业务发展的前面,在业务需要处理更多访问和服务之前,就已经做好充足准备,当业务需要时,只需要购买或者租用服务器简单部署实施就可以了,技术团队亦可高枕无忧。反之,设计和技术走在业务的后面,采购来的机器根本就没办法加入集群,勉强加了进去,却发现瓶颈不在这里,系统整体处理能力依然上不去。技术团队每天加班,却总是拖公司发展的后腿。架构师对网站伸缩性的把握,一线之间,天堂和地狱。
高手定律:这个世界只有遇不到的问题,没有解决不了的问题,高手之所以成为高手,是因为他们遇到了常人很难遇到的问题,并解决了。所以百度有很多广告搜索的高手,淘宝有很多海量数据的高手,QQ有很多高并发业务的高手,原因大抵
如此。一个100万用户的网站,不会遇到1亿用户同时在线的问题;一个拥有100万件商品网站的工程师,可能无法理解一个拥有10亿件商品网站的架构。
救世主定律:遇到问题,分析问题,最后总能解决问题。
如果遇到问题就急匆匆地从外面挖一个高手,然后指望高手如探囊取物般轻松搞定,最后怕是只有彼此抱怨和伤害。许多问题只是看起来一样,具体问题总是要具体对待的,没有银弹,没有救世主。所以这个定律准确地说应该是“没有救世主定律”。
如对本文有疑问,请提交到交流论坛,广大热心网友会为你解答!! 点击进入论坛

