Web前端基础(W3C标准/html/CSS/JavaScript/XPath/JSON)
Web前端基础
爬虫主要是和网页打交道,了解Web前端的知识是非常重要的。
Web前端的知识范围非常广泛,不可能面面俱到和深入讲解,本章主要是抽取Web前端中和爬虫相关的知识点进行讲解,帮助读者了解这些必备的知识,为之后的Python爬虫开发打下基础。
2.1 W3C标准
如果说你只知道Web前端的一个标准,估计肯定是W3C标准了。W3C,即万维网联盟,是Web技术领域最具权威和影响力的国际中立性技术标准机构。万维网联盟(W3C)标准不是某一个标准,而是一系列标准的集合。网页主要由三部分组成:结构(Structure)、表现(Presentation)和行为(Behavior)。对应的标准也分三方面:结构化标准语言主要包括XHTML和XML,表现标准语言主要包括CSS,行为标准主要包括对象模型(如W3C DOM)、ECMAScript等。本节我们主要讲解HTML、CSS、JavaScript、Xpath和JSON等5个部分,基本上覆盖了爬虫开发中需要了解的Web前端基本知识。
2.1.1 HTML
什么是HTML标记语言?HTML不是编程语言,是一种表示网页信息的符号标记语言。标记语言是一套标记,HTML使用标记来描述网页。Web浏览器的作用是读取HTML文档,并以网页的形式显示出它们。浏览器不会显示HTML标记,而是使用标记来解释页面的内容。
HTML语言的特点包括:
·可以设置文本的格式,比如标题、字号、文本颜色、段落,等等。
·可以创建列表。
·可以插入图像和媒体。
·可以建立表格。
·超链接,可以使用鼠标点击超链接来实现页面之间的跳转。
下面从HTML的基本结构、文档设置标记、图像标记、表格和超链接五个方面讲解。
1.HTML的基本结构
首先在浏览器上访问google网站(如图2-1所示),右键查看源代码,如图2-2所示。

图2-1 谷歌网站首页图2-2 谷歌首页源代码
从谷歌首页的源代码中可以分析出HTML的基本结构:
·<html>内容</html>:HTML文档是由<html></html>包裹,这是HTML文档的文档标记,也称为HTML开始标记。这对标记分别位于网页的最前端和最后端,<html>在最前端表示网页的开始,</html>在最后端表示网页的结束。
·<head>内容</head>:HTML文件头标记,也称为HTML头信息开始标记。用来包含文件的基本信息,比如网页的标题、关键字,在
<head></head>内可以放<title></title>、<meta></meta>、<style></style>等标记。注意:在<head></head>标记内的内容不会在浏览器中显示。
·<title>内容</title>:HTML文件标题标记。网页的“主题”,显示在浏览器的窗口的左上边。
·<body>内容</body>:<body>...</body>是网页的主体部分,在此标记之间可以包含如<p></p>、<h1></h1>、<br>、<hr>等等标记,正是由这些内容组成了我们所看见的网页。
·<meta>内容</meta>:页面的元信息(meta-information)。提供有关页面的元信息,比如针对搜索引擎和更新频度的描述和关键词。
注意meta标记必须放在head元素里面。
2.文档设置标记
文档设置标记分为格式标记和文本标记。下面通过一个标准的HTML文档对格式标记进行讲解,文档如下所示:
<html>
<head>
<title>Python爬虫开发与项目实战</title> <meta charset="UTF-8"> </head>
<body> 文档设置标记<br> <p>这是段落。</p> <p>这是段落。</p> <p>这是段落。</p> <hr> <center>居中标记1</center> <center>居中标记2</center> <hr>
<pre> [00:00](music)
[00:28]你我皆凡人,生在人世间;[00:35]终日奔波苦,一刻不得闲;
[00:43]既然不是仙,难免有杂念;
</pre> <hr> <p> [00:00](music)
[00:28]你我皆凡人,生在人世间;[00:35]终日奔波苦,一刻不得闲;
[00:43]既然不是仙,难免有杂念;
</p>
<hr> <br> <ul> <li>Coffee</li> <li>Milk</li> </ul> <ol type="A"> <li>Coffee</li> <li>Milk</li> </ol> <dl> <dt>计算机</dt> <dd>用来计算的仪器 ... ...</dd> <dt>显示器</dt> <dd>以视觉方式显示信息的装置 ... ...</dd> </dl> <div > <h3>这是标题</h3> <p>这是段落。</p> </div> </body> </html>
在浏览器中打开运行,效果如图2-3所示。

图2-3 运行效果图
格式标记包括:
·<br>:强制换行标记。让后面的文字、图片、表格等等,显示在下一行。
·<p>:换段落标记。换段落,由于多个空格和回车在HTML中会被等效为一个空格,所以HTML中要换段落就要用<p>,<p>段落中也可以包含<p>段落。例如:<p>This is a paragraph.</p>。
·<center>:居中对齐标记。让段落或者是文字相对于父标记居中显示。
·<pre>:预格式化标记。保留预先编排好的格式,常用来定义计算机源代码。和<p>进行一下对比,就可以理解。
·<li>:列表项目标记。每一个列表使用一个<li>标记,可用在有序列表(<ol>)和无序列表(<ul>)中。
·<ul>:无序列表标记。<ul>声明这个列表没有序号。
·<ol>:有序列表标记。可以显示特定的一些顺序。有序列表的type属性值“1”表示阿拉伯数字1.2.3等等;默认type属性值“A”表示大小字母A、B、C等等;上面的程序使用属性“a”,这表示小写字母a、b、c等等;“Ⅰ”表示大写罗马数字Ⅰ、Ⅱ、Ⅲ、Ⅳ等等;“ⅰ”表示小写罗马数字ⅰ、ⅱ、ⅲ、ⅳ等等。注意:列表可以进行嵌套。
·<dl><dt><dd>:定义型列表。对列表条目进行简短说明。
·<hr>:水平分割线标记。可以用作段落之间的分割线。
·<div>:分区显示标记,也称为层标记。常用来编排一大段的
HTML段落,也可以用于将表格式化,和<p>很相似,可以多层嵌套使用。
接下来通过一个HTML文档对文本标记进行讲解,文档如下所示:
<html> <head>
<title>Python爬虫开发与项目实战</title> <meta charset="UTF-8"> </head> <body> Hn标题标记---->> <br> <h1>Python爬虫</h1> <h2>Python爬虫</h2> <h3>Python爬虫</h3> <h4>Python爬虫</h4> <h5>Python爬虫</h5> <h6>Python爬虫</h6> font标记---->> <font size="1">Python爬虫</font> <font size="3">Python爬虫</font> <font size="7">Python爬虫</font> <font size="7" color="red" face="微软雅黑">Python爬虫</font> <font size="7" color="red" face="宋体">Python爬虫</font> <font size="7" color="red" face="新细明体">Python爬虫</font> <br> B标记加粗---->> <b>Python爬虫</b> <br> i标记斜体---->> <i>Python爬虫</i> <br> sub下标标记---->>
2<sub>2</sub> <br> sup上标标记---->> 2<sup>2</sup> <br> 引用标记---->> <cite>Python爬虫</cite> <br> em标记表示强调,显示为斜体---->> <em>Python爬虫</em> <br> strong标记表示强调,加粗显示---->> <strong>Python爬虫</strong> <br> small标记,可以显示小一号字体,可以嵌套使用---->> <small>Python爬虫</small> <small><small>Python爬虫</small></small> <small><small><small>Python爬虫</small></small></small> <br> big标记,显示大一号的字体---->> <big>Python爬虫</big> <big><big>Python爬虫</big></big> <br> u标记是显示下划线---->> <big><big><big><u>Python爬虫</u></big></big></big> <br> </body>
</html>
在浏览器中打开运行,效果如图2-4所示。
其中文本标记包括:
·<hn>:标题标记。共有6个级别,n的范围为1~6,不同级别对应不同显示大小的标题,h1最大,h6最小。
·<font>:字体设置标记。用来设置字体的格式,一般有三个常用属性:size(字体大小),<font size=“14px”>;color(颜色),
<font color=“red”>;face(字体),<font face=“微软雅黑”>。
·<b>:粗字体标记。
·<i>:斜字体标记。
·<sub>:文字下标字体标记。
·<sup>:文字上标字体标记。
·<tt>:打印机字体标记。
·<cite>:引用方式的字体,通常是斜体。
·<em>:表示强调,通常显示为斜体字。
·<strong>:表示强调,通常显示为粗体字。
·<small>:小型字体标记。

·<big>:大型字体标记。
·<u>:下划线字体标记。
图2-4 运行效果图
3.图像标记
<img>称为图像标记,用来在网页中显示图像。使用方法为:
<img src=“路径/文件名.图片格式”width=“属性值”height=“属性值”border=“属性值”alt=“属性值”>。<img>标记主要包括以下属性:
·src属性用来指定我们要加载的图片的路径、图片的名称以及图片格式。
·width属性用来指定图片的宽度,单位为px、em、cm、mm。
·height属性用来指定图片的高度,单位为px、em、cm、mm。
·border属性用来指定图片的边框宽度,单位为px、em、cm、mm。
·alt属性有三个作用:1)当网页上的图片被加载完成后,鼠标移动到上面去,会显示这个图片指定的属性文字;2)如果图像没有下载或者加载失败,会用文字来代替图像显示;3)搜索引擎可以通过这个属性的文字来抓取图片。
我们可以在浏览器上访问博客园首页,对博客园首页的图片进行审查,就可以看到的img标记的使用方法,如图2-5所示。
图2-5 img标记
注意 <img>为单标记,不需要使用</img>闭合。在加载图像文件的时候,文件的路径、文件名或者文件格式错误,将无法加载图片。
4.超链接的使用
爬虫开发中经常需要抽取链接,链接的引用使用的是<a>标记。
<a>标记的基本语法:<a href=“链接地址”target=“打开方式”
name=“页面锚点名称”>链接文字或者图片</a>。<a>标记主要包括以下属性:
·href属性值是链接的地址,链接的地址可以是一个网页,也可以是一个视频、图片、音乐等。
·target属性用来定义超链接的打开方式。当属性值为_blank时,作用是在一个新的窗口中打开链接;当属性值为_self(默认值)时,作用是在当前窗口中打开链接;当属性值为_parent时,作用是在在父窗口中打开页面;当属性值为_top时,在顶层窗口中打开文件。
·name属性用来指定页面的锚点名称。
5.表格
表格的基本结构包括<table>、<caption>、<tr>、<td>和<th>等标记。
<table>标记的基本格式为<table属性1=“属性值1”属性2=“属性值2”......>表格内容</table>。table标记有以下常见属性:
·width属性:表示表格的宽度,它的值可以是像素(px)也可以是父级元素的百分比(%)。
·height属性:表示表格的高度,它的值可以是像素(px)也可以是父级元素的百分比(%)。
·border属性:表示表格外边框的宽度。
·align属性用来表示表格的显示位置。left居左显示,center居中显示,right居右显示。
·cellspacing属性:单元格之间的间距,默认是2px,单位为像素。
·cellpadding属性:单元格内容与单元格边框的显示距离,单位为像素。
·frame属性用来控制表格边框最外层的四条线框。void(默认值)表示无边框;above表示仅顶部有边框;below表示仅有底部边框;
hsides表示仅有顶部边框和底部边框;lhs表示仅有左侧边框;rhs表示仅有右侧边框;vsides表示仅有左右侧边框;border表示包含全部4个边框。
·rules属性用来控制是否显示以及如何显示单元格之间的分割线。属性值none(默认值)表示无分割线;all表示包括所有分割线;rows表示仅有行分割线;clos表示仅有列分割线;groups表示仅在行组和列组之间有分割线。
<caption>标记用于在表格中使用标题。<caption>属性的插入位置,直接位于<table>属性之后,<tr>表格行之前。<caption>标记中
align属性可以取四个值:top表示标题放在表格的上部;bottom表示标题放在表格的下部;left表示标题放在表格的左部;right表示标题放在表格的右部。
<tr>标记用来定义表格的行,对于每一个表格行,都是由一对
<tr>...</tr>标记表示,每一行<tr>标记内可以嵌套多个<td>或者<th>标记。<tr>标记中的常见属性包括:
·bgcolor属性用来设置背景颜色,格式为bgcolor=“颜色值”。
·valign属性用来设置垂直方向对齐方式,格式为valign=“值”。值为bottom时,表示靠顶端对齐;值为top时,表示靠底部对齐;值为middle时,表示居中对齐。
·align属性用来设置水平方向对齐方式,格式为align=“值”。值为left时,表示靠左对齐;值为right时,表示靠右对齐;值为center时,表示居中对齐。
<td>和<th>都是单元格的标记,其必须嵌套在<tr>标记内,成对出现。<th>是表头标记,通常位于首行或者首列,<th>中的文字默认会被加粗,而<td>不会。<td>是数据标记,表示该单元格的具体数据。
<td>和<th>两者的标记属性都是一样的,常用属性如下:
·bgcolor设置单元格背景。
·align设置单元格水平对齐方式。
·valign设置单元格垂直对齐方式。
·width设置单元格宽度。
·height设置单元格高度。
·rowspan设置单元格所占行数。
·colspan设置单元格所占列数。
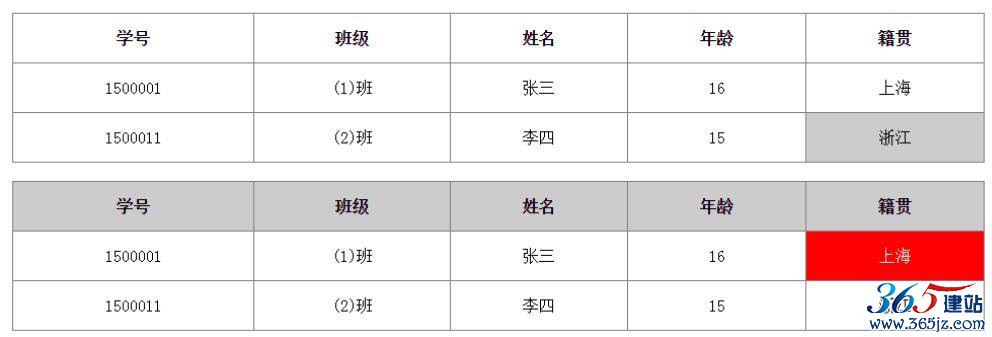
下面通过一个HTML文档来演示表格的使用,文档如下:
下面通过一个HTML文档来演示表格的使用,文档如下:
<html>
<head>
<title>学生信息表</title>
<meta charset="UTF-8">
</head>
<body>
<table width="960" align="center" border="1" rules="all" cellpadding="15"> <tr> <th>学号</th> <th>班级</th> <th>姓名</th> <th>年龄</th> <th>籍贯</th></tr> <tr align="center"> <td>1500001</td> <td>(1)班</td> <td>张三</td> <td>16</td> <td>上海</td> </tr> <tr align="center"> <td>1500011</td> <td>(2)班</td> <td>李四</td> <td>15</td> <td bgcolor="# ccc">浙江</td> </tr> </table> <br/> <table width="960" align="center" border="1" rules="all" cellpadding= "15"> <tr bgcolor="# ccc"> <th>学号</th> <th>班级</th> <th>姓名</th> <th>年龄</th> <th>籍贯</th> </tr> <tr align="center"><td>1500001</td> <td>(1)班</td> <td>张三</td> <td>16</td> <td bgcolor="red"><font color="white">上海</font></td> </tr> <tr align="center"> <td>1500011</td> <td>(2)班</td> <td>李四</td> <td>15</td> <td>浙江</td> </tr> </table> </body> </html>
在浏览器中打开运行,效果如图2-6所示。
2.1.2 CSS
CSS指层叠样式表(Cascading Style Sheets),用来定义如何显示HTML元素,一般和HTML配合使用。CSS样式表的目的是为了解决内容与表现分离的问题,即使同一个HTML文档也能表现出外观的多样化。在HTML中使用CSS样式的方式,一般有三种做法:
·内联样式表:CSS代码直接写在现有的HTML标记中,直接使用style属性改变样式。例如,<body style="background-color:green;margin:0; padding:0;"></body>。
·嵌入式样式表:CSS样式代码写在<style type="text/css"></style>标记之间,一般情况下嵌入式CSS样式写在<head></head>之间。
·外部样式表:CSS代码写一个单独的外部文件中,这个CSS样式文件以“.css”为扩展名,在<head>内(不是在<style>标记内)使用<link>标记将CSS样式文件链接到HTML文件内。例如,<link rel="StyleSheet" type="text/css" href="style.css">。
CSS规则由两个主要的部分构成:选择器,以及一条或多条声明。
选择器通常是需要改变样式的HTML元素。每条声明由一个属性和一个值组成。属性(property)是希望设置的样式属性(styleattribute)。每个属性有一个值。属性和值由冒号分开。例如:
h1{color:blue;font-size:12px}。其中h1为选择器,color和font-size是属性,blue和12px是属性值,这句话的意思是将h1标记中的颜色设置为蓝色,字体大小为12px。根据选择器的定义方式,可以将样式表的定义分成三种方式:
·HTML标记定义:上面举的例子就是使用的这种方式。假如想修改<p>...</p>的样式,可以定义CSS:p{属性:属性值;属性1:属性值1}。p可以叫做选择器,定义了标记中内容所执行的样式。一个选择器可以控制若干个样式属性,他们之间需要用英语的“;”隔开,最后一个可以不加“;”。
·ID选择器定义:ID选择器可以为标有特定ID的HTML元素指定特定的样式。HTML元素以ID属性来设置ID选择器,CSS中ID选择器以“#”来定义。假如定义为#word{text-align:center;color:red;},就将HTML中ID为word的元素设置为居中,颜色为红色。
·class选择器定义:class选择器用于描述一组元素的样式,class选择器有别于ID选择器,它可以在多个元素中使用。class选择器在HTML中以class属性表示,在CSS中,class选择器以一个点“.”号显示。例如,.center{text-align:center;}将所有拥有center类的HTML元素设为居中。当然也可以指定特定的HTML元素使用class,例如,p.center{text-align:center;}是对所有的p元素使用class=“center”,让该元素的文本居中。
介绍完选择器,接着说一下CSS中一些常见的属性。常见属性主要说明一下颜色属性、字体属性、背景属性、文本属性和列表属性。
1.颜色属性
颜色属性color用来定义文本的颜色,可以使用以下方式定义颜色:
·颜色名称,如color:green。
·十六进制,如color:#ff6600。
·简写方式,如color:#f60。
·RGB方式,如rgb(255,255,255),红(R)、绿(G)、蓝(B)的取值范围均为0~255·RGBA方式,如color:rgba(255,255,255,1),RGBA表示
Red(红色)、Green(绿色)、Blue(蓝色)和Alpha的(色彩空间)透明度。
2.字体属性
可以使用字体属性定义文本形式,有如下方法:
·font-size定义字体大小,如font-size:14px。
·font-family定义字体,如font-family:微软雅黑,serif。字体之间可以使用“,”隔开,以确保当字体不存在的时候直接使用下一个字体。
·font-weight定义字体加粗,取值有两种方式。一种是使用名称,如normal(默认值)、bold(粗)、bolder(更粗)、lighter(更细);一种是使用数字,如100、200、300~900,400=normal,而700=bold。
3.背景属性
可以用背景属性定义背景颜色、背景图片、背景重复和背景的位置,内容如下:
·background-color用来定义背景的颜色,用法参考颜色属性。
·background-image用来定义背景图片,如background-image:
url(图片路径),也可以设置为background-image:none,表示不使用图片。
·background-repeat用来定义背景重复方式。取值为repeat,表示整体重复平铺;取值为repeat-x,表示只在水平方向平铺;取值为
repeat-y,表示只在垂直方向平铺;取值为no-repeat,表示不重复。
·background-position用来定义背景位置。在横向上,可以取
left、center、right;在纵向上可以取top、center、bottom。
·简写方式可以简化背景属性的书写,同时定义多个属性,格式为background:背景颜色url(图像)重复位置。如background:
#f60url(images/bg、jpg)no-repeat top center。
4.文本属性
可以用文本属性设置行高、缩进和字符间距,具体如下:
·text-align设置文本对齐方式,属性值可以取left、center、right。
·line-height设置文本行高,属性值可以取具体数值,来设置固定的行高值。也可以取百分比,是基于字体大小的百分比行高。
·text-indent代表首行缩进,如text-indent:50px,意思是首行缩进50个像素。
·letter-spacing用来设置字符间距。属性值默认是normal,规定字符间没有额外的空间;可以设置具体的数值(可以是负值),如letter-spacing:3px;可以取inherit,从父元素继承letter-spacing属性的值。
5.列表
在HTML中,有两种类型的列表:无序和有序。其实使用CSS,可以列出进一步的样式,并可用图像作列表项标记。接下来主要讲解以下几种属性:
·list-style-type用来指明列表项标记的类型。常用的属性值有:
none(无标记)、disc(默认,标记是实心圆)、circle(标记是空心圆)、square(标记是实心方块)、decimal(标记是数字)、
decimal-leading-zero(0开头的数字标记)、lower-roman(小写罗马数字i、ii、iii、iv、v等)、upper-roman(大写罗马数字I、II、III、IV、V等)、lower-alpha(小写英文字母a、b、c、d、e等)、upper-alpha(大写英文字母A、B、C、D、E等)。例如,ul.a{list-style-type:circle;}是将class选择器的值为a的ul标记设置为空心圆标记。
·list-style-position用来指明列表项中标记的位置。属性值可以取inside、outside和inherit。inside指的是列表项标记放置在文本以内,且环绕文本根据标记对齐。outside为默认值,保持标记位于文本的左侧,列表项标记放置在文本以外,且环绕文本不根据标记对齐。
inherit规定应该从父元素继承list-style-position属性的值。
·list-style-image用来设置设置图像列表标记。属性值可以为URL(图像的路径)、none(默认无图形被显示)、inherit(从父元素继承list-style-image属性的值)。例如,ul{list-style-image:
url(‘image.gif’);},意思是给ul标记前面的标记设置为image.gif图片。
2.1.3 JavaScript
JavaScript是一种轻量级的脚本语言,和Python语言是一样的,只不过JavaScript是由浏览器进行解释执行。JavaScript可以插入HTML页面中,可由所有的现代浏览器执行。由于JavaScript是一门新的编程语言,知识点很多,本节不进行深入讲解,主要介绍一下JavaScript的用法和基本语法。大家如果想深入学习,需要额外看一些教程。
如何使用JavaScript呢?主要有直接插入代码和外部引用js文件两种做法:
<script src="/static/js/jquery.js"></script> </head> <body> python爬虫
</body> </html>
这样/static/js/jquery.js就会被浏览器执行。把JavaScript代码放入一个单独的.js文件中更利于维护代码,并且多个页面可以各自引用同一份.js文件,减少程序员编码量。在页面中多次编写JavaScript代码,浏览器按照顺序依次执行。
一般在正常的开发中都是采用上述两种做法结合的方式,之后在做Python爬虫开发时会经常见到。
2.1.4 XPath
XPath是一门在XML文档中查找信息的语言,被用于在XML文档中通过元素和属性进行导航。XPath虽然是被设计用来搜寻XML文档,不过它也能很好地在HTML文档中工作,并且大部分浏览器也支持通过XPath来查询节点。在Python爬虫开发中,经常使用XPath查找提取网页中的信息,因此XPath非常重要。
XPath既然叫Path,就是以路径表达式的形式来指定元素,这些路径表达式和我们在常规的电脑文件系统中看到的表达式非常相似。
由于XPath一开始是被用来搜寻XML文档的,所以接下来就以XML文档为例子来讲解XPath。接下来从节点、语法、轴和运算符等四个方面讲解XPath的使用。
1.XPath节点
在XPath中,XML文档是被作为节点树来对待的,有七种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及文档(根)节点。树的根被称为文档节点或者根节点。以下面的XML文档为例进行说明,文档如下:
<xml version="1.0" encoding="ISO-8859-1"> <classroom> <student> <id>1001</id> <name lang="en">marry</name>
<age>20</age> <country>China</country> </student> </classroom>
上面的XML文档中的节点例子包括:<classroom>(文档节点)、<id>1001</id>(元素节点)、lang=“en”(属性节点)、marry(文本)。
接着说一下节点关系,包括父(Parent)、子(Children)、同胞(Sibling)、先辈(Ancestor)、后代(Descendant)。在上面的文档中:
·student元素是id、name、age以及country元素的父。
·id、name、age以及country元素都是student元素的子。
·id、name、age以及country元素都是同胞节点,拥有相同的父节点。
·name元素的先辈是student元素和classroom元素,也就是此节点的父、父的父等。
·classroom的后代是id、name、age以及country元素,也就是此节点的子,子的子等。
2.XPath语法
XPath使用路径表达式来选取XML文档中的节点或节点集。节点是沿着路径(path)或者步(steps)来选取的。接下来的重点是如何选取节点,下面给出一个XML文档进行分析:
<xml version="1.0" encoding="ISO-8859-1"> <classroom> <student> <id>1001</id> <name lang="en">marry</name> <age>20</age> <country>China</country> </student> <student> <id>1002</id> <name lang="en">jack</name> <age>25</age> <country>USA</country> </student> </classroom>
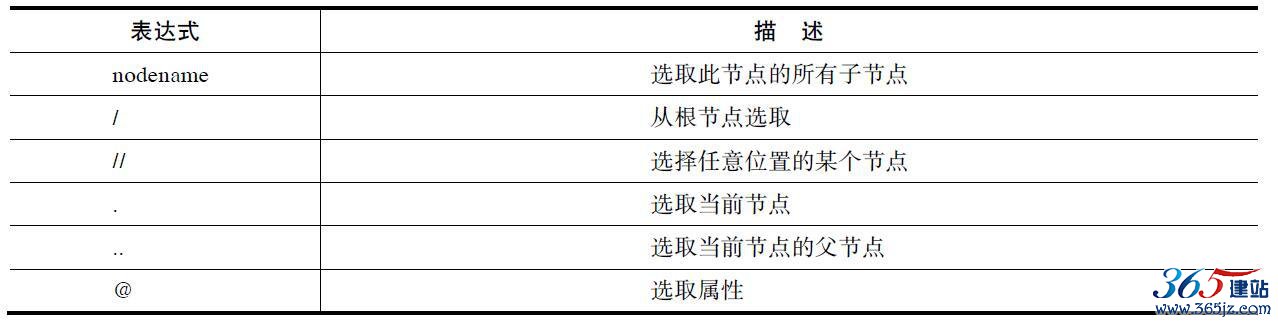
首先列举出一些常用的路径表达式进行节点的选取,如表2-2所示。
表2-2 路径表达式
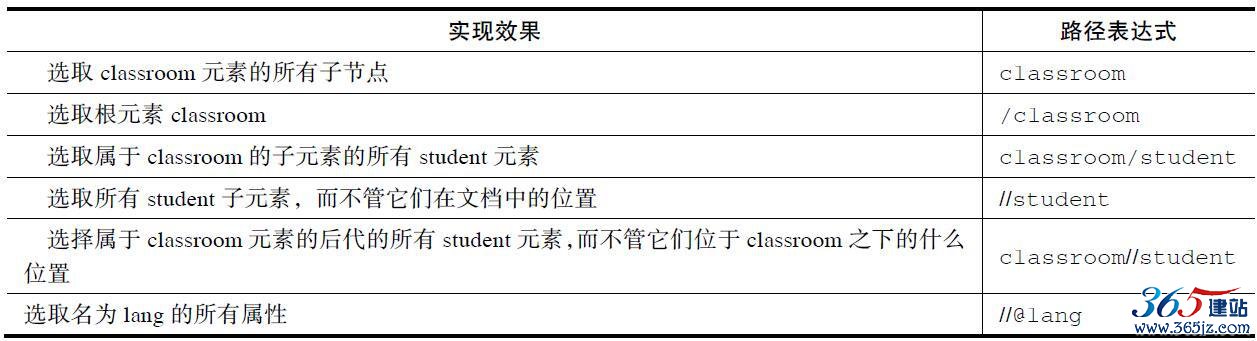
通过表2-2中的路径表达式,我们尝试着对上面的文档进行节点选取。以表格的形式进行说明,如表2-3所示。
表2-3 节点选取示例
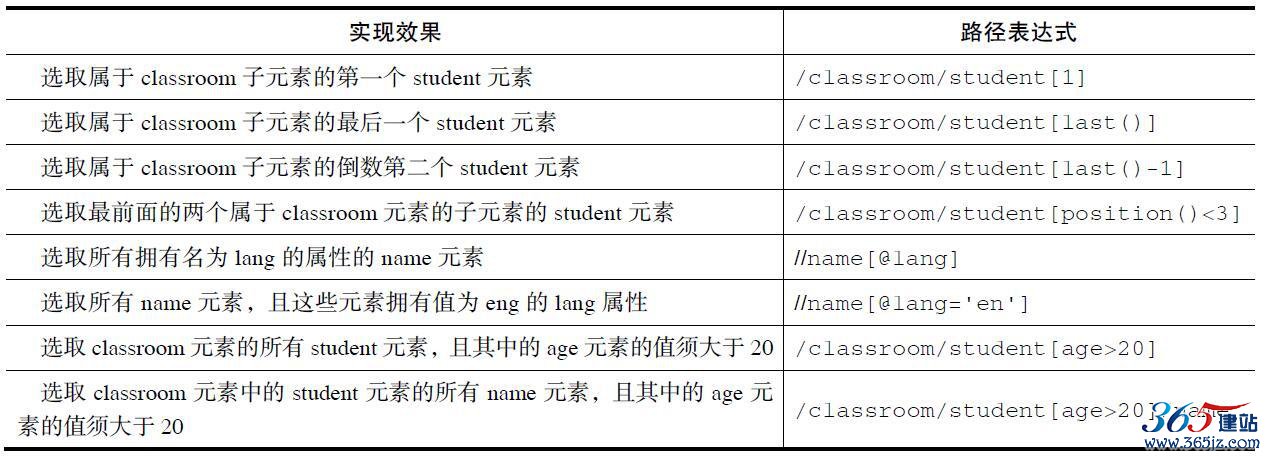
上面选取的例子最后实现的效果都是选取了所有符合条件的节点,是否能选取某个特定的节点或者包含某一个指定的值的节点呢?这就需要用到谓语,谓语被嵌在方括号中,接下来通过表格2-4来解释谓语的用法。
表2-4 谓语示例

XPath在进行节点选取的时候可以使用通配符“*”匹配未知的元素,同时使用操作符“|”一次选取多条路径,还是通过一个表格进行演示,如表2-5所示。
表2-5 通配符“*”与“1”操作符
3.XPath轴
轴定义了所选节点与当前节点之间的树关系。在Python爬虫开发中,提取网页中的信息会遇到这种情况:首先提取到一个节点的信息,然后想在在这个节点的基础上提取它的子节点或者父节点,这时候就会用到轴的概念。轴的存在会使提取变得更加灵活和准确。
在说轴的用法之前,需要了解位置路径表达式中的相对位置路径、绝对位置路径和步的概念。位置路径可以是绝对的,也可以是相对的。绝对路径起始于正斜杠(/),而相对路径不会这样。在两种情况中,位置路径均包括一个或多个步,每个步均被斜杠分割:/step/
step/...(绝对位置路径),step/step/...(相对位置路径)。
步(step)包括:轴(axis)、节点测试(node-test)、零个或者更多谓语(predicate),用来更深入地提炼所选的节点集。步的语法为:轴名称::节点测试[谓语],大家可能觉比较抽象,通过之后的示例分析,会明白如何使用它。
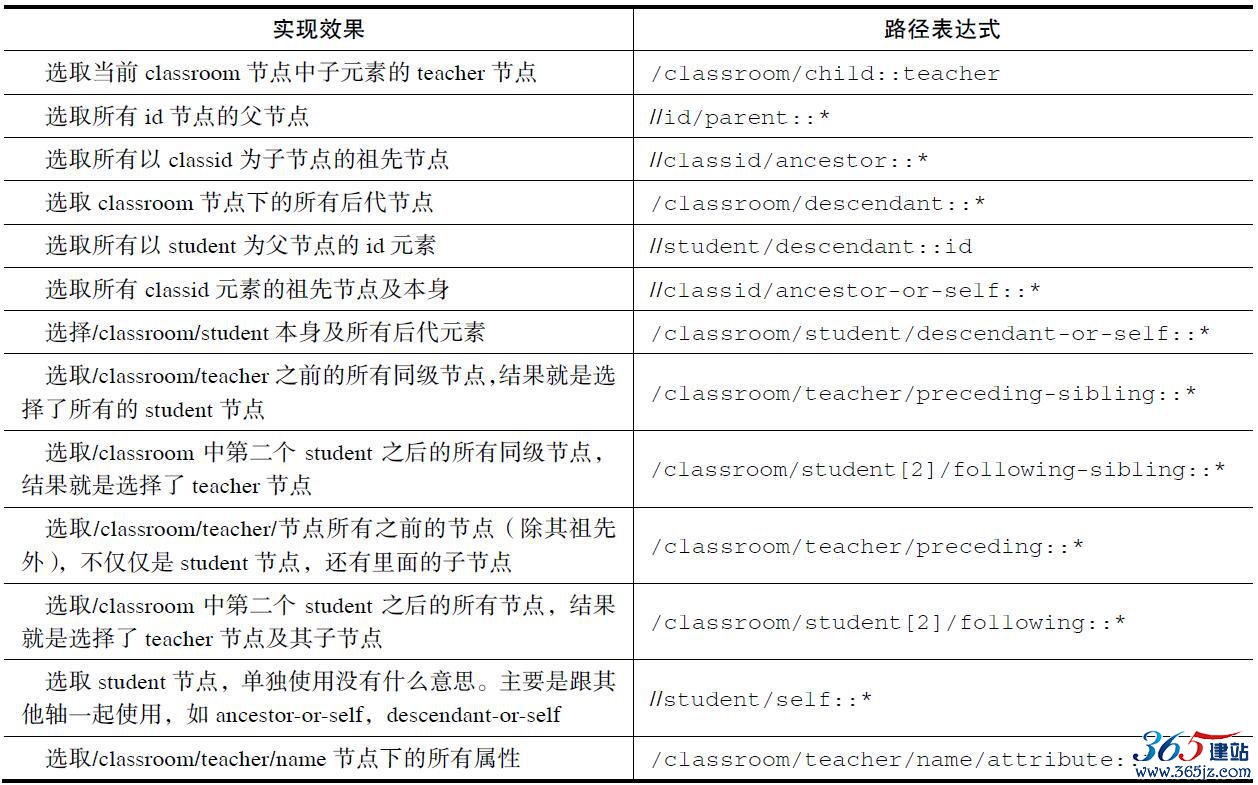
表2-6列举了XPath轴中使用的节点集。

表2-6 XPath轴
首先给出一个XML文档,实例分析就按照这个文档来进行,文档
如下:
<xml version="1.0" encoding="ISO-8859-1"> <classroom> <student> <id>1001</id> <name lang="en">marry</name> <age>20</age> <country>China</country> </student> <student> <id>1002</id> <name lang="en">jack</name> <age>25</age> <country>USA</country> </student> <teacher> <classid>1</classid> <name lang="en">tom</name> <age>50</age> <country>USA</country> </teacher> </classroom>
针对上面的文档进行示例演示,如表2-7所示。
表2-7 XPath轴示例分析
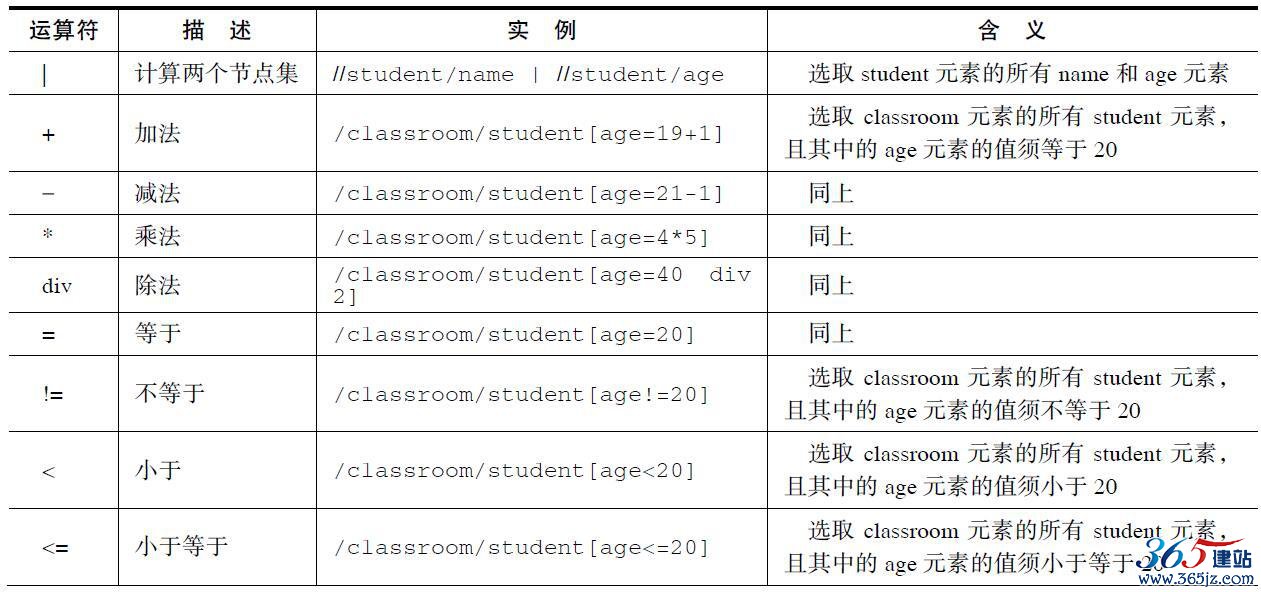
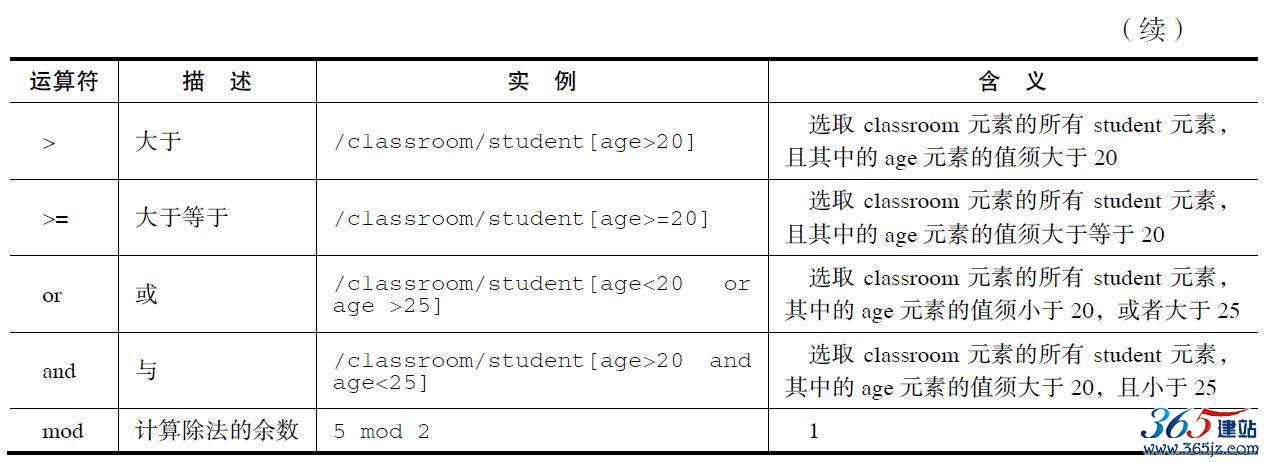
4.XPath运算符
XPath表达式可返回节点集、字符串、逻辑值以及数字。表2-8列举了可用在XPath表达式中的运算符。
表2-8 XPath运算符示例分析
2.1.5 JSON
JSON是JavaScript对象表示法(JavaScript Object Notation),用于存储和交换文本信息。JSON比XML更小、更快、更易解析,因此
JSON在网络传输中,尤其是Web前端中运用非常广泛。JSON使用
JavaScript语法来描述数据对象,但是JSON仍然独立于语言和平台。
JSON解析器和JSON库支持许多不同的编程语言,其中就包括Python。
下面主要讲解一下JSON的语法,具体的存储解析放到第5章中进行讲解。JSON语法非常简单,主要包括以下几个方面:
·JSON名称/值对。JSON数据的书写格式是:名称/值对。名称/
值对包括字段名称(在双引号中),紧接着是一个冒号,最后是值。
例如,“name”:“qiye”,非常像Python中字典。
·JSON值。JSON值可以是:数字(整数或浮点数)、字符串(在双引号中)、逻辑值(true或false)、数组(在方括号中)、对象(在花括号中)、null。
·JSON对象。JSON对象在花括号中书写,对象可以包含多个名称/值对。例如:{“name”:“qiye”,“age”:“20”},其实就是Python中的字典。
·JSON数组。JSON数组在方括号中书写,数组可包含多个对象。例如:{“reader”:[{“name”:“qiye”,“age”:“20”},{“name”:“marry”,“age”:“21”}]},这里对象“reader”是包含两个对象的数组。
如对本文有疑问,请提交到交流论坛,广大热心网友会为你解答!! 点击进入论坛

