Python爬虫之Web端协议网页登录POST分析(知乎/百度云)实例
Python爬虫之Web端协议网页登录POST分析
本节探讨的是那些需要登录之后才能进行页面爬取的情况,属于深层次的网页爬取。我们将讲一些大家熟悉的例子,比如爬取论坛或者贴吧的内容,这种网站对权限的管理非常严格,不同的角色权限,对应的网页内容是不同的。假如你没有登录该论坛或贴吧,相当于游客权限,基本上爬取不到任何有价值的数据。本节要做的就是完成登录获取Cookie这一步,现在的网页登录基本上都是使用表单提交
POST请求来完成验证。接下来就讲解登录POST请求中需要注意的情况。
10.1.1 隐藏表单分析
大家在分析POST请求时经常碰到这种情况,通过FireBug截获POST请求,发现POST出去的数据比我们在表单中填写的数据多,而且这些数据的内容每次还变化,这非常影响我们使用Python发送
POST请求进行模拟登录。下面以知乎(https://www.zhihu.com/#signin)为例,如图10-1所示。
图10-1 登录知乎
打开Firebug,打开网络监听,输入账号和密码进行登录。截获的请求如图10-2所示。
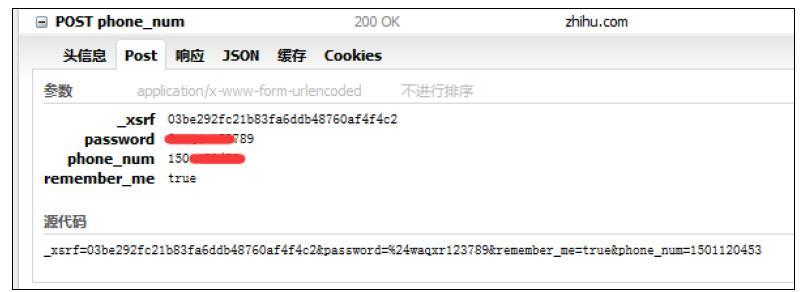
POST内容如下:
_xsrf=03be292fc21b83fa6ddb48760af4f4c2 password=XXXXXXXX phone_num=XXXXXXXX remember_me=true
我使用的是手机号登录,账号密码使用XXXXXXXX代替。大家发现phone_num、password、remember_me这三个字段是我们在表单中输入或者选中的,除了这三个还多了一个_xsrf参数,做过Web前端的朋友肯定认识这个字段,这是用来防跨站请求伪造的。那这个参数在哪呢?我们需要使用_xsrf这个参数模拟登录。
这就需要Firebug强大的搜索功能,将_xsrf后面的值03be292fc21b83fa6ddb48760af4f4c2填入搜索框中并回车,如图10-3所示。
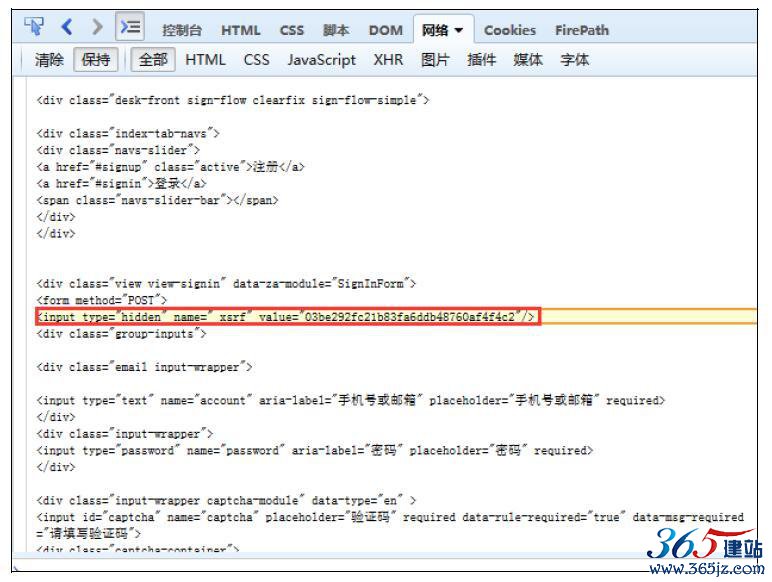
图10-4 _xsrf位置
知道了_xsrf的位置,既可以使用Beautiful Soup提取其中的值,也可以直接使用正则表达式提取。这次使用正则表达式进行提取,然后使用Requests提交POST请求。代码如下:
# coding:utf-8 # 构造 Request headers
import re
import requestsdef get_xsrf(session):
'''_xsrf 是一个动态变化的参数,从网页中提取'''
index_url = 'http://www.zhihu.com'
# 获取登录时需要用到的_xsrf
index_page = session.get(index_url, headers=headers)
html = index_page.text
pattern = r'name="_xsrf" value="(.*)"'
# 这里的_xsrf 返回的是一个list
_xsrf = re.findall(pattern, html)
return _xsrf[0] agent = 'Mozilla/5.0 (Windows NT 5.1; rv:33.0) Gecko/20100101 Firefox/33.0'
headers = { 'User-Agent': agent
} session = requests.session()
_xsrf = get_xsrf(session)
post_url = 'http://www.zhihu.com/login/phone_num'
postdata = { '_xsrf': _xsrf, 'password': 'xxxxxxxx', 'remember_me': 'true', 'phone_num': 'xxxxxxx', } login_page = session.post(post_url, data=postdata, headers=headers)
login_code = login_page.text
print(login_page.status_code)
print(login_code)
登录成功的输出结果为:
200 {"r":0, "msg": "\u767b\u5f55\u6210\u529f"}
10.1.2 加密数据分析
上面看到的知乎账号和密码都是使用明文进行发送,但是为了安全,很多网站都会将密码进行加密,然后添加一系列附加的参数到
POST请求中,而且还有验证码,分析难度和知乎登录完全不是一个量级。下面我们就进行一下挑战,分析百度POST登录方式,强化大家的分析能力。由于百度登录使用的是同一套加密规则,所以这次就以百度云盘的登录为例进行分析,整个分析过程分为三个部分。
第一部分首先打开FireBug,访问http://yun.baidu.com/,监听网络数据,如图10-5所示。
图10-5 百度网盘
操作流程:
1)输入账号和密码。
2)点击登录。(第一次POST登录。)
3)这时候会出现验证码,输入验证码。
4)最后点击登录成功上线。(第二次POST登录成功。)在一次成功的登录过程中,我们需要点击两次登录按钮,也就出现了两次POST请求,如图10-6所示。
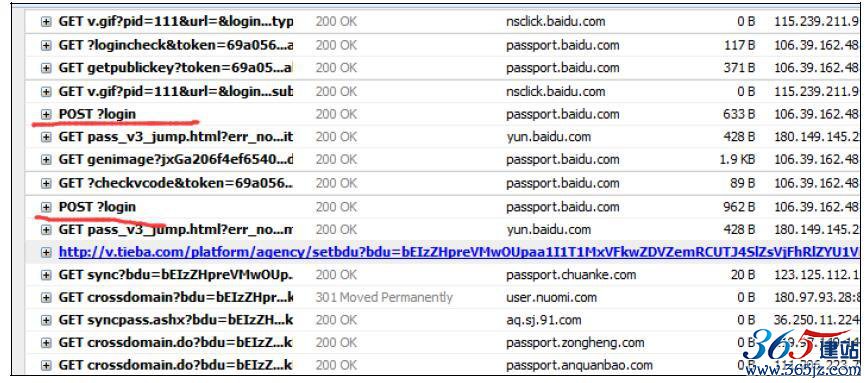
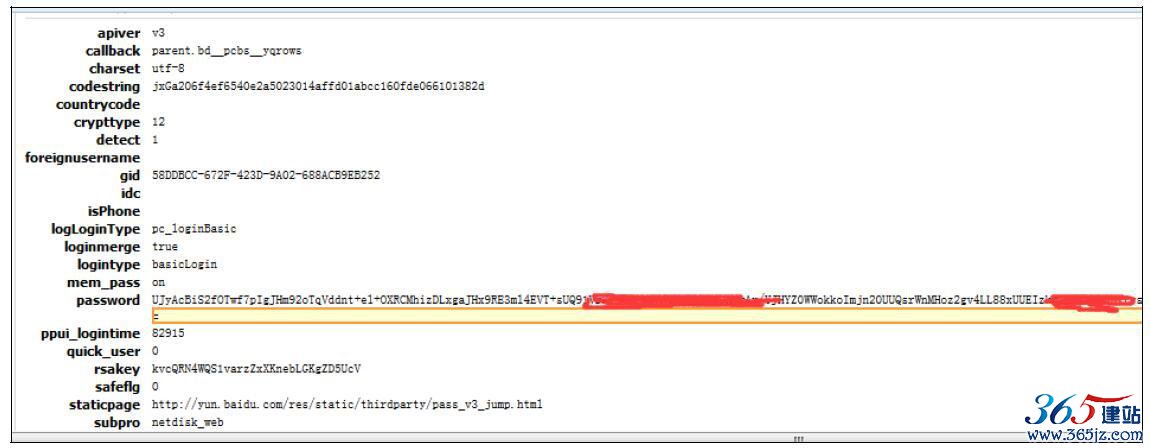
图10-6 两次POST请求
将上面两次的POST请求记录下来,记录完成之后,清空cookie,再进行一次成功的登录,用于比较POST请求字段中那些是会变化的,那些是不会变化的。两次登录四次POST请求,我们将这四次POST
请求命名为post1_1、post1_2、post2_1、post2_2,以便区分是哪一次登录的哪一个POST请求。
现在先关注post2_2和post1_2,这是两次登录最后成功的POST请求,如图10-7所示:

图10-7 post2_2参数
通过比较post2_2和post1_2,我们可以发现一些字段是变化的,一些是不变的,如表10-1所示。
表10-1 POST参数值状态表
通过表10-1,我们可以了解到那些变化的字段,这也是我们着重要分析的地方。接着分析一下变化的参数,看哪些是可以轻易获取的。
·callback:不清楚是什么,不知道怎么获取。
·codestring:不清楚是什么,不知道怎么获取。
·gid:一个生成的ID号,不知道怎么获取。
·password:加密后的密码,不知道怎么获取。
·ppui_logintime:时间,不知道怎么获取。
·rsakey:RSA加密的密钥(可以推断出密码肯定是经过了RSA加密),不知道怎么获取。
·token:访问令牌,不知道怎么获取。
·tt:时间戳,可以使用Python的time模块生成。
·verifycode:验证码,可以轻易获取验证码图片并获取验证码值。
通过上面的分析,又确定了tt、verifycode参数的提取方式,现在只剩下callback、codestring、gid、password、ppui_logintime、rsakey、token等参数的分析。
第二部分既然已经知道了需要确定的参数,接下来要做的是确定callback、codestring、gid、password、ppui_logintime、rsakey、token这些参数是在哪一次登录过程的哪一个post请求中产生的。将post2_1和post2_2的请求参数进行比较,如图10-8是post2_1请求的内容,可以和图10-7进行比较,以发现参数的变化。
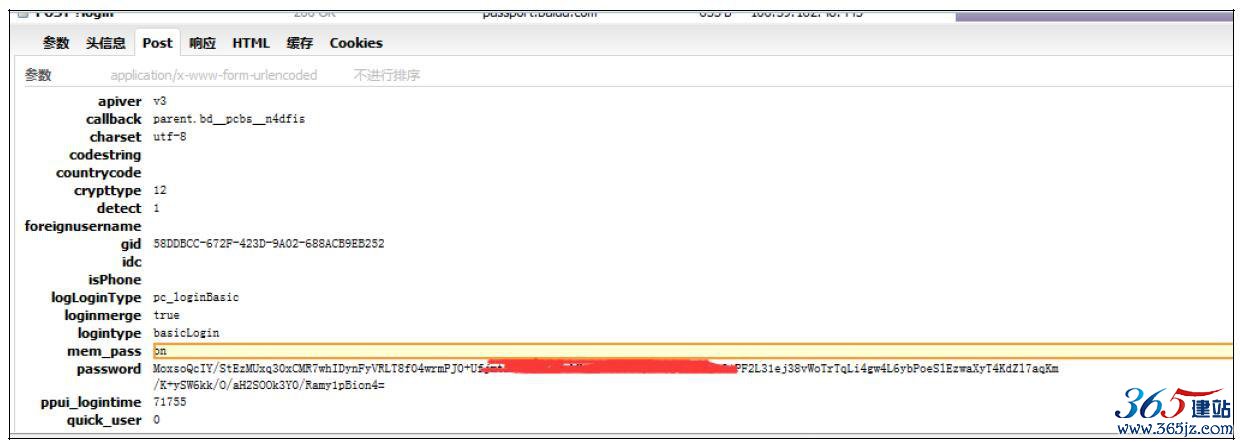
图10-8 post2_1参数
通过比较,参数变化如表10-2所示。
表10-2 post2_1和post2_2参数值对比
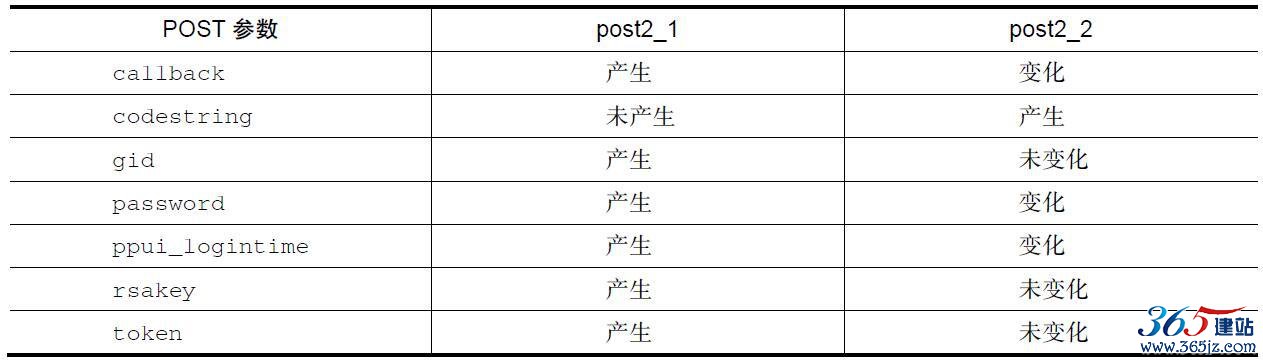
通过上表我们看到出现明显变化的是codestring,从无到有。可以基本上确定codestring是在post2_1之后产生的,所以codestring这个字段应该是在post2_1的响应中找到。果不其然,如图10-9所示:
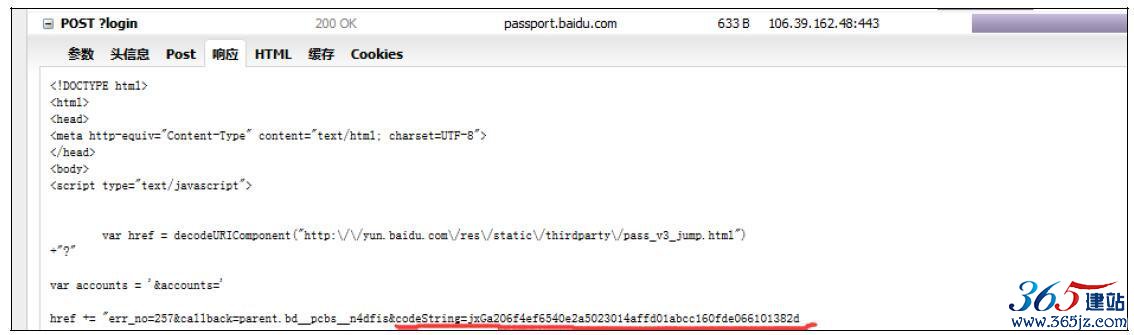
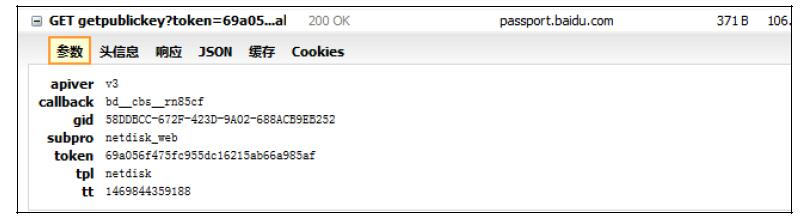
图10-9 codestring参数
codestring这个字段的获取位置已经确定。
接着分析post2_1已经产生,post2_1内容没有发生变化的参数:
gid、rsakey、token。这些参数可以确定是在post2_1请求发送之前就已经产生,根据网络响应的顺序,从下到上,看看能不能发现一些敏感命名的链接。在post2_1的不远处,发现了一个敏感链接:https://
passport.baidu.com/v2/getpublickeytoken=69a056f475fc955dc16215ab66a985af&tpl=netdisk&
subpro=netdisk_web&apiver=v3&tt=1469844359188&gid=58DDBCC-672F-423D-9A02-688ACB9EB252&callback=bd__cbs__rn85cf,如图10-10所示。

图10-10 敏感链接
通过查看响应我们找到rsakey,虽然在响应中变成了key,可是值是一样的。通过之前的信息,我们知道密码是通过RSA加密的,所以响应中的publickey可能是公钥,这个要重点注意,如图10-11所示:
图10-11 敏感链接响应
还可以发现callback参数,参数中出现callback字段,之后响应中也出现了callback字段的值将响应包裹,由此可以推断callback字段可能只是进行标识作用,不参与实际的参数校验。
通过对这个敏感链接的请求参数可以得出以下结论:gid和token
可以得到rsakey参数。
接着分析gid参数和token参数。直接在FireBug的搜索框中输入
token,进行搜索。搜索两到三次,可以发现token的出处位于https://passport.baidu.com/v2/api/getapi&tpl=netdisk&subpro=netdisk_web&apiver=v3&tt=1469844296412&class=login&gid=58DDBCC-672F-423D-9A02-688ACB9EB252&logintype=basicLogin&callback=bd__cbs__cmkxjj,如图10-12所示:
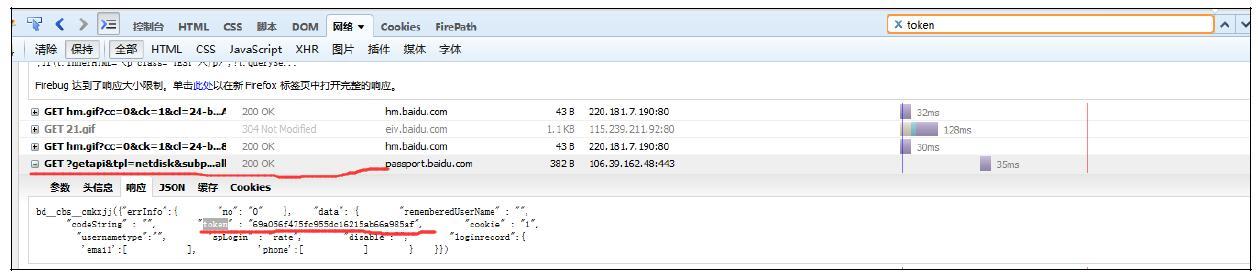
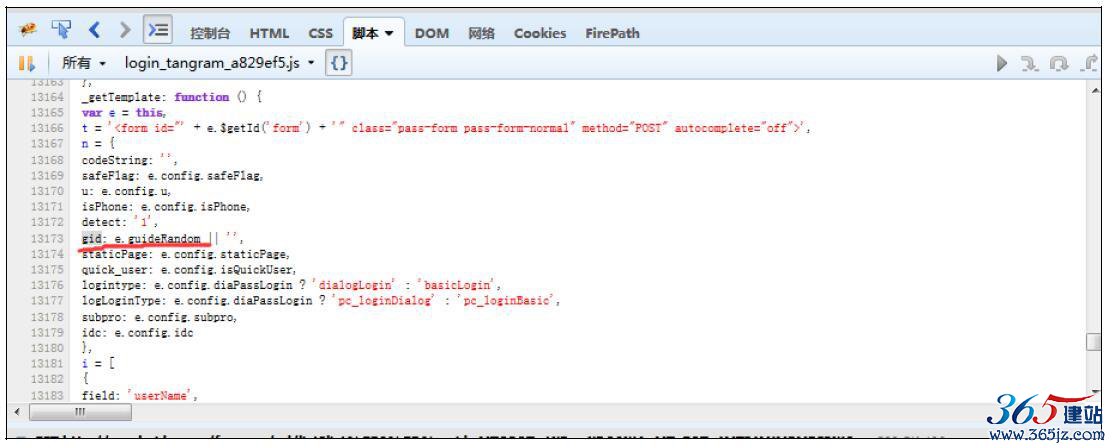
图10-12 token出处
通过这个链接的get参数,我们可以得到如下的结论:通过gid可以得出Token。
最后分析一下gid参数。依旧是通过搜索的办法,很快在http://passport.bdimg.com/passApi/js/login_tangram_a829ef5.js中找到了gid
的出处,如图10-13所示:
图10-13 gid位置
格式化脚本之后,咱们看一下这个gid是怎么产生的。通过gid:e.guideRandom,我们可以知道gid是由guideRandom这个函数产生的,接着在脚本中搜索这个函数,如图10-14所示:
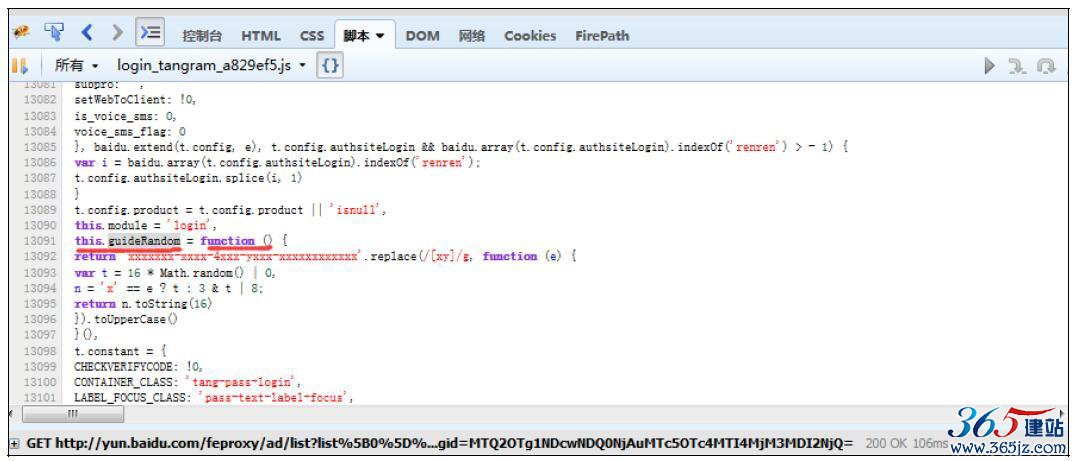
最后找到这个函数的原型,通过代码可以看到,这是随机生成的字符串,这就好办了。函数原型如下:
gid = this.guideRandom = function () { return 'xxxxxxx-xxxx-4xxx-yxxx-xxxxxxxxxxxx'.replace(/[xy]/g, function (e) { var t = 16 * Math.random() | 0, n='x'==et:3&t|8;
return n.toString(16)
}).toUpperCase()
}()
图10-14 guideRandom函数
最后将第二部分进行一下总结:
·codestring:从第一次POST之后的响应中提取出来
·gid:由一个已知函数guideRandom随机产生,可以通过调用函数获取
·token:https://passport.baidu.com/v2/api/getapi&tpl=netdisk&subpro=netdisk_web&apiver=v3&tt=1469844296412&class=login&gid=58DDBCC-672F-423D-9A02-688ACB9EB252&logi
ntype=basicLogin&callback=bd__cbs__cmkxjj,将gid带入链接,获取响应中的token·rsakey:https://passport.baidu.com/v2/getpublickeytoken=69a056f475fc955dc16215ab66a985af&tpl=netdisk&
subpro=netdisk_web&apiver=v3&tt=1469844359188&gid=58DDBCC-672F-423D-9A02-688ACB9EB252&callback=bd__cbs__rn85c,将获取的gid和token带入链接,从响应中可以提取出rsakey
第三部分最后还剩callback、password和ppui_logintime参数。通过之前的分析,可以了解到callback可能没啥用,所以放到后面再分析。一般来说password是最难分析的,所以也放到后面分析。
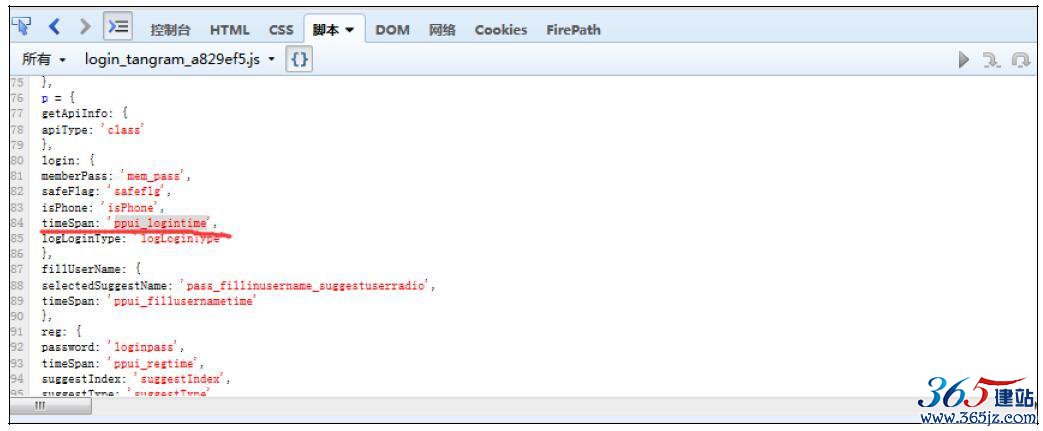
接下来分析ppui_logintime,搜索ppui_logintime,在下面的链接中找到了ppui_logintime的出处:http://passport.bdimg.com/passApi/js/login_tangram_a829ef5.js,如图10-15所示。
找到了timeSpan:’ppui_logintime‘,接着搜索timeSpan,如图10-16所示。
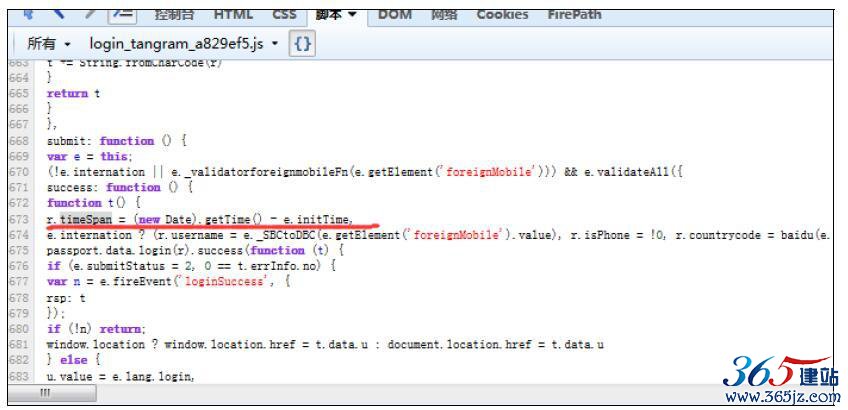
找到了r.timeSpan=(new Date).getTime()-e.initTime,接着搜索initTime,如图10-17所示。
通过上面的代码我们可以知道ppui_logintime可能是从输入登录信息,一直到点击登录按钮提交的这段时间,可以直接使用之前的
POST请求所发送的数据,没有什么影响。
图10-15 ppui_logintime参数
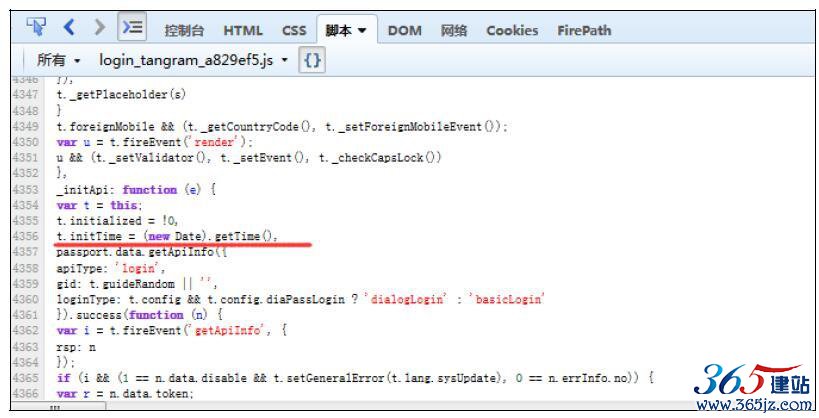
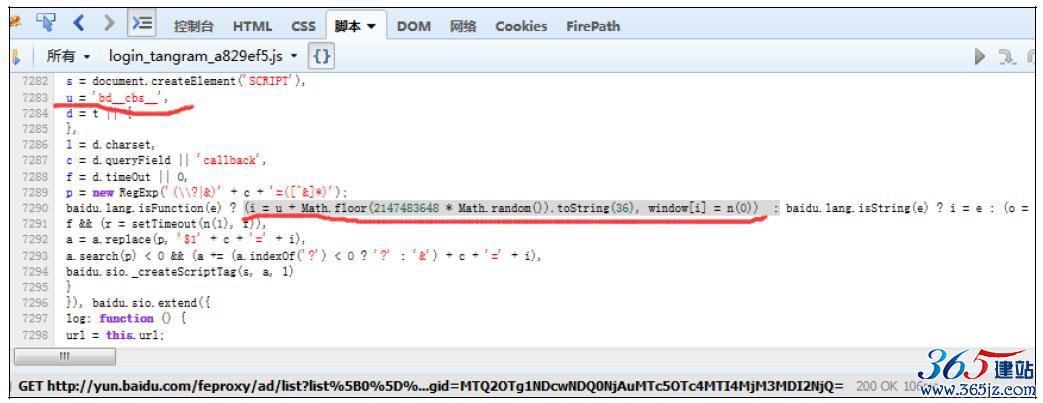
图10-16 timeSpan
图10-17 initTime
接着分析callback参数,搜索callback,我们将可以找到callback的生成方式,如图10-18所示。
callback生成方式为:
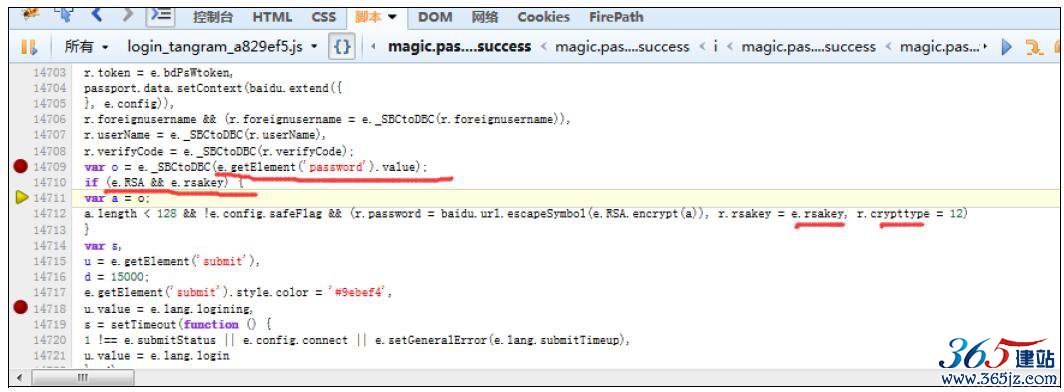
图10-18 callback
最后分析password的加密方式,搜索password,发现敏感内容,在http://passport.bdimg.com/passApi/js/login_tangram_a829ef5.js
链接中,如图10-19所示。
图10-19 password
通过设置断点,动态调试可以知道,password是通过公钥pubkey对密码进行加密,最后对输出进行base64编码,即为最后的加密密码。
通过以上三部分的分析,基本上将POST所有参数的产生方式都确定了。最后我们进行模拟登录,其中使用到了pyv8引擎,可以直接运行JavaScript代码,这样生成gid和callback的JavaScript函数可以直接使用,不用转化为Python语言,不过转化也是非常简单的。完整的登录代码如下,每一部分我都进行了详细的注释,大家也可以从我的
GitHub上进行下载:https://github.com/qiyeboy/baidulogin.git。
# coding:utf-8 import base64 import json
import re
from Crypto.Cipher import PKCS1_v1_5 from Crypto.PublicKey import RSA import PyV8 from urllib import quote
import requests
import time
if __name__=='__main__':
s = requests.Session()
s.get('http://yun.baidu.com')
js='''
function callback(){ return 'bd__cbs__'+Math.floor(2147483648 * Math.random()).toString(36)
} function gid(){ return 'xxxxxxx-xxxx-4xxx-yxxx-xxxxxxxxxxxx'.replace(/[xy]/g, function (e)
{ var t = 16 * Math.random() | 0, n = 'x' == e t : 3 & t | 8;
return n.toString(16)
}).toUpperCase()
}
'''
ctxt = PyV8.JSContext()
ctxt.enter()
ctxt.eval(js)
########### 获取gid############################# 3 gid = ctxt.locals.gid()
########### 获取callback############################# 3 callback1 = ctxt.locals.callback()
########### 获取token############################# 3 tokenUrl="https:// passport.baidu.com/v2/api/getapi&tpl=netdisk&subpro=net
disk_web&apiver=v3" \ "&tt=%d&class=login&gid=%s&logintype=basicLogin&callback=%s"
%(time.
time()*1000,gid,callback1)
token_response = s.get(tokenUrl)
pattern = re.compile(r'"token"\s*:\s*"(\w+)"')
match = pattern.search(token_response.text)
if match:
token = match.group(1)
else:
raise Exception
########### 获取callback############################# 3 callback2 = ctxt.locals.callback()
########### 获取rsakey和pubkey############################# 3 rsaUrl = "https:// passport.baidu.com/v2/getpublickeytoken=%s&" \ "tpl=netdisk&subpro=netdisk_web&apiver=v3&tt=%d&gid=%s&
callback= %s"%(token,time.time()*1000,gid,callback2)
rsaResponse = s.get(rsaUrl)
pattern = re.compile("\"key\"\s*:\s*'(\w+)'")
match = pattern.search(rsaResponse.text)
if match:
key = match.group(1)
print key
else:
raise Exception
pattern = re.compile("\"pubkey\":'(.+)'")
match = pattern.search(rsaResponse.text)
if match:
pubkey = match.group(1)
print pubkey
else:
raise Exception
################ 加密password######################## 3 password = 'xxxxxxx'# 填上自己的密码
pubkey = pubkey.replace('\\n','\n').replace('\\','')
rsakey = RSA.importKey(pubkey)
cipher = PKCS1_v1_5.new(rsakey)
password = base64.b64encode(cipher.encrypt(password))
print password
########### 获取callback############################# 3 callback3 = ctxt.locals.callback()
data={
'apiver':'v3', 'charset':'utf-8', 'countrycode':'', 'crypttype':12, 'detect':1, 'foreignusername':'', 'idc':'', 'isPhone':'', 'logLoginType':'pc_loginBasic', 'loginmerge':True, 'logintype':'basicLogin', 'mem_pass':'on', 'quick_user':0, 'safeflg':0, 'staticpage':'http://yun.baidu.com/res/static/thirdparty/pass_v3_jump.html'
, 'subpro':'netdisk_web', 'tpl':'netdisk', 'u':'http://yun.baidu.com/', 'username':'xxxxxxxxx',# 填上自己的用户名
'callback':'parent.'+callback3, 'gid':gid,'ppui_logintime':71755, 'rsakey':key, 'token':token, 'password':password, 'tt':'%d'%(time.time()*1000), }
########### 第一次post############################# 3 post1_response = s.post('https:// passport.baidu.com/v2/api/login',data=data)
pattern = re.compile("codeString=(\w+)&")
match = pattern.search(post1_response.text)
if match:
########### 获取codeString############################# 3 codeString = match.group(1)
print codeString
else:
raise Exception
data['codestring']= codeString
############# 获取验证码################################### verifyFail = True
while verifyFail:
genimage_param = ''
if len(genimage_param)==0:
genimage_param = codeString
verifycodeUrl="https:// passport.baidu.com/cgi-bin/genimage%s"%
genimage_param
verifycode = s.get(verifycodeUrl)
############# 下载验证码##################################
# with open('verifycode.png','wb') as codeWriter:
codeWriter.write(verifycode.content)
codeWriter.close()
############# 输入验证码##################################
#
verifycode = raw_input("Enter your input verifycode: ");
callback4 = ctxt.locals.callback()
############# 检验验证码##################################
# checkVerifycodeUrl='https:// passport.baidu.com/v2/' \ 'checkvcode&token=%s' \ '&tpl=netdisk&subpro=netdisk_web&apiver=v3&tt=%d' \ '&verifycode=%s&codestring=%s' \ '&callback=%s'%(token,time.time()*1000,quote(verifycode), codeString,callback4)
print checkVerifycodeUrl
state = s.get(checkVerifycodeUrl)
print state.text
if state.text.find(u'验证码错误')!=-1:
print '验证码输入错误...已经自动更换...'
callback5 = ctxt.locals.callback()
changeVerifyCodeUrl = "https:// passport.baidu.com/v2/
reggetcodestr" \ "&token=%s" \ "&tpl=netdisk&subpro=netdisk_web&apiver=v3" \ "&tt=%d&fr=login&" \ "vcodetype=de94eTRcVz1GvhJFsiK5G+ni2k2Z78PYR
xUaRJLEmxdJO5ftPhviQ3/ JiT9vezbFtwCyqdkNWSP29oeOvYE0SYPocOGL+
iTafSv8pw" \ "&callback=%s"%(token,time.time()*1000,callb ack5)
print changeVerifyCodeUrl
verifyString = s.get(changeVerifyCodeUrl)
pattern = re.compile('"verifyStr"\s*:\s*"(\w+)"')
match = pattern.search(verifyString.text)
if match:
########### 获取verifyString#############################
3 verifyString = match.group(1)
genimage_param = verifyString
print verifyString
else:
verifyFail = False
raise Exception
else:
verifyFail = False
data['verifycode']= verifycode
########### 第二次post############################# 3 data['ppui_logintime']=81755 #################################################### # 特地说明,大家会发现第二次的post出去的密码是改变的,为什么我这里没有变化呢?
# 是因为RSA加密,加密密钥和密码原文即使不变,每次加密后的密码都是改变的,RSA有随机因子的关系
# 所以我这里不需要在对密码原文进行第二次加密了,直接使用上次加密后的密码即可,是没有问题的。
############################################################
##############
post2_response = s.post('https:// passport.baidu.com/v2/api/login',data=data)
if post2_response.text.find('err_no=0')!=-1:
print '登录成功'
else:
print '登录失败'
注意 以上百度登录分析过程仅限于当时的加密情况,如果之后换了登录方式,以上代码可能会失效,但是分析方法不变
如对本文有疑问,请提交到交流论坛,广大热心网友会为你解答!! 点击进入论坛

