linux中awk命令用法和与正则表达式截取字符串详解
awk是一个强大的文本分析工具,相对于grep的查找,sed的编辑,awk在其对数据分析并生成报告时,显得尤为强大。简单来说awk就是把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行各种分析处理。
awk有3个不同版本: awk、nawk和gawk,未作特别说明,一般指gawk,gawk 是 AWK 的 GNU 版本。
awk是行处理器: 相比较屏幕处理的优点,在处理庞大文件时不会出现内存溢出或是处理缓慢的问题,通常用来格式化文本信息
awk处理过程: 依次对每一行进行处理,然后输出
awk命令形式:
awk [-F|-f|-v] ‘BEGIN{} //{command1; command2} END{}’ file
[-F|-f|-v] 大参数,-F指定分隔符,-f调用脚本,-v定义变量 var=value
' ' 引用代码块
BEGIN 初始化代码块,在对每一行进行处理之前,初始化代码,主要是引用全局变量,设置FS分隔符
// 匹配代码块,可以是字符串或正则表达式
{} 命令代码块,包含一条或多条命令
; 多条命令使用分号分隔
END 结尾代码块,在对每一行进行处理之后再执行的代码块,主要是进行最终计算或输出结尾摘要信息
特殊要点:
$0 表示整个当前行
$1 每行第一个字段
NF 字段数量变量
NR 每行的记录号,多文件记录递增
FNR 与NR类似,不过多文件记录不递增,每个文件都从1开始
\t 制表符
\n 换行符
FS BEGIN时定义分隔符
RS 输入的记录分隔符, 默认为换行符(即文本是按一行一行输入)
~ 匹配,与==相比不是精确比较
!~ 不匹配,不精确比较
== 等于,必须全部相等,精确比较
!= 不等于,精确比较
&& 逻辑与
|| 逻辑或
+ 匹配时表示1个或1个以上
/[0-9][0-9]+/ 两个或两个以上数字
/[0-9][0-9]*/ 一个或一个以上数字
FILENAME 文件名
OFS 输出字段分隔符, 默认也是空格,可以改为制表符等
ORS 输出的记录分隔符,默认为换行符,即处理结果也是一行一行输出到屏幕
-F'[:#/]' 定义三个分隔符
print & $0
print 是awk打印指定内容的主要命令
awk '{print}' /etc/passwd == awk '{print $0}' /etc/passwd
awk '{print " "}' /etc/passwd //不输出passwd的内容,而是输出相同个数的空行,进一步解释了awk是一行一行处理文本
awk '{print "a"}' /etc/passwd //输出相同个数的a行,一行只有一个a字母
awk -F":" '{print $1}' /etc/passwd
awk -F: '{print $1; print $2}' /etc/passwd //将每一行的前二个字段,分行输出,进一步理解一行一行处理文本
awk -F: '{print $1,$3,$6}' OFS="\t" /etc/passwd //输出字段1,3,6,以制表符作为分隔符
-f指定脚本文件
awk -f script.awk file
BEGIN{
FS=":"
}
{print $1} //效果与awk -F":" '{print $1}'相同,只是分隔符使用FS在代码自身中指定
awk 'BEGIN{X=0} /^$/{ X+=1 } END{print "I find",X,"blank lines."}' test
I find 4 blank lines.
ls -l|awk 'BEGIN{sum=0} !/^d/{sum+=$5} END{print "total size is",sum}' //计算文件大小
total size is 17487
-F指定分隔符
$1 指指定分隔符后,第一个字段,$3第三个字段, \t是制表符
一个或多个连续的空格或制表符看做一个定界符,即多个空格看做一个空格
awk -F":" '{print $1}' /etc/passwd
awk -F":" '{print $1 $3}' /etc/passwd //$1与$3相连输出,不分隔
awk -F":" '{print $1,$3}' /etc/passwd //多了一个逗号,$1与$3使用空格分隔
awk -F":" '{print $1 " " $3}' /etc/passwd //$1与$3之间手动添加空格分隔
awk -F":" '{print "Username:" $1 "\t\t Uid:" $3 }' /etc/passwd //自定义输出
awk -F: '{print NF}' /etc/passwd //显示每行有多少字段
awk -F: '{print $NF}' /etc/passwd //将每行第NF个字段的值打印出来
awk -F: 'NF==4 {print }' /etc/passwd //显示只有4个字段的行
awk -F: 'NF>2{print $0}' /etc/passwd //显示每行字段数量大于2的行
awk '{print NR,$0}' /etc/passwd //输出每行的行号
awk -F: '{print NR,NF,$NF,"\t",$0}' /etc/passwd //依次打印行号,字段数,最后字段值,制表符,每行内容
awk -F: 'NR==5{print}' /etc/passwd //显示第5行
awk -F: 'NR==5 || NR==6{print}' /etc/passwd //显示第5行和第6行
route -n|awk 'NR!=1{print}' //不显示第一行
//匹配代码块
//纯字符匹配 !//纯字符不匹配 ~//字段值匹配 !~//字段值不匹配 ~/a1|a2/字段值匹配a1或a2
awk '/mysql/' /etc/passwd
awk '/mysql/{print }' /etc/passwd
awk '/mysql/{print $0}' /etc/passwd //三条指令结果一样
awk '!/mysql/{print $0}' /etc/passwd //输出不匹配mysql的行
awk '/mysql|mail/{print}' /etc/passwd
awk '!/mysql|mail/{print}' /etc/passwd
awk -F: '/mail/,/mysql/{print}' /etc/passwd //区间匹配
awk '/[2][7][7]*/{print $0}' /etc/passwd //匹配包含27为数字开头的行,如27,277,2777...
awk -F: '$1~/mail/{print $1}' /etc/passwd //$1匹配指定内容才显示
awk -F: '{if($1~/mail/) print $1}' /etc/passwd //与上面相同
awk -F: '$1!~/mail/{print $1}' /etc/passwd //不匹配
awk -F: '$1!~/mail|mysql/{print $1}' /etc/passwd
IF语句
必须用在{}中,且比较内容用()扩起来
awk -F: '{if($1~/mail/) print $1}' /etc/passwd //简写
awk -F: '{if($1~/mail/) {print $1}}' /etc/passwd //全写
awk -F: '{if($1~/mail/) {print $1} else {print $2}}' /etc/passwd //if...else...
条件表达式
== != > >=
awk -F":" '$1=="mysql"{print $3}' /etc/passwd
awk -F":" '{if($1=="mysql") print $3}' /etc/passwd //与上面相同
awk -F":" '$1!="mysql"{print $3}' /etc/passwd //不等于
awk -F":" '$3>1000{print $3}' /etc/passwd //大于
awk -F":" '$3>=100{print $3}' /etc/passwd //大于等于
awk -F":" '$3<1{print $3}' /etc/passwd //小于
awk -F":" '$3<=1{print $3}' /etc/passwd //小于等于
逻辑运算符
&& ||
awk -F: '$1~/mail/ && $3>8 {print }' /etc/passwd //逻辑与,$1匹配mail,并且$3>8
awk -F: '{if($1~/mail/ && $3>8) print }' /etc/passwd
awk -F: '$1~/mail/ || $3>1000 {print }' /etc/passwd //逻辑或
awk -F: '{if($1~/mail/ || $3>1000) print }' /etc/passwd
数值运算
awk -F: '$3 > 100' /etc/passwd
awk -F: '$3 > 100 || $3 < 5' /etc/passwd
awk -F: '$3+$4 > 200' /etc/passwd
awk -F: '/mysql|mail/{print $3+10}' /etc/passwd //第三个字段加10打印
awk -F: '/mysql/{print $3-$4}' /etc/passwd //减法
awk -F: '/mysql/{print $3*$4}' /etc/passwd //求乘积
awk '/MemFree/{print $2/1024}' /proc/meminfo //除法
awk '/MemFree/{print int($2/1024)}' /proc/meminfo //取整
输出分隔符OFS
awk '$6 ~ /FIN/ || NR==1 {print NR,$4,$5,$6}' OFS="\t" netstat.txt
awk '$6 ~ /WAIT/ || NR==1 {print NR,$4,$5,$6}' OFS="\t" netstat.txt
//输出字段6匹配WAIT的行,其中输出每行行号,字段4,5,6,并使用制表符分割字段
输出处理结果到文件
①在命令代码块中直接输出 route -n|awk 'NR!=1{print > "./fs"}'
②使用重定向进行输出 route -n|awk 'NR!=1{print}' > ./fs
格式化输出
netstat -anp|awk '{printf "%-8s %-8s %-10s\n",$1,$2,$3}'
printf表示格式输出
%格式化输出分隔符
-8长度为8个字符
s表示字符串类型
打印每行前三个字段,指定第一个字段输出字符串类型(长度为8),第二个字段输出字符串类型(长度为8),
第三个字段输出字符串类型(长度为10)
netstat -anp|awk '$6=="LISTEN" || NR==1 {printf "%-10s %-10s %-10s \n",$1,$2,$3}'
netstat -anp|awk '$6=="LISTEN" || NR==1 {printf "%-3s %-10s %-10s %-10s \n",NR,$1,$2,$3}'
IF语句
awk -F: '{if($3>100) print "large"; else print "small"}' /etc/passwd
small
small
small
large
small
small
awk -F: 'BEGIN{A=0;B=0} {if($3>100) {A++; print "large"} else {B++; print "small"}} END{print A,"\t",B}' /etc/passwd
//ID大于100,A加1,否则B加1
awk -F: '{if($3<100) next; else print}' /etc/passwd //小于100跳过,否则显示
awk -F: 'BEGIN{i=1} {if(i<NF) print NR,NF,i++ }' /etc/passwd
awk -F: 'BEGIN{i=1} {if(i<NF) {print NR,NF} i++ }' /etc/passwd
另一种形式
awk -F: '{print ($3>100 ? "yes":"no")}' /etc/passwd
awk -F: '{print ($3>100 ? $3":\tyes":$3":\tno")}' /etc/passwd
while语句
awk -F: 'BEGIN{i=1} {while(i<NF) print NF,$i,i++}' /etc/passwd
7 root 1
7 x 2
7 0 3
7 0 4
7 root 5
7 /root 6
数组
netstat -anp|awk 'NR!=1{a[$6]++} END{for (i in a) print i,"\t",a[i]}'
netstat -anp|awk 'NR!=1{a[$6]++} END{for (i in a) printf "%-20s %-10s %-5s \n", i,"\t",a[i]}'
9523 1
9929 1
LISTEN 6
7903 1
3038/cupsd 1
7913 1
10837 1
9833 1
入门实例
假设last -n 5的输出如下
[root@www ~]# last -n 5 <==仅取出前五行 root pts/1 192.168.1.100 Tue Feb 10 11:21 still logged in root pts/1 192.168.1.100 Tue Feb 10 00:46 - 02:28 (01:41) root pts/1 192.168.1.100 Mon Feb 9 11:41 - 18:30 (06:48) dmtsai pts/1 192.168.1.100 Mon Feb 9 11:41 - 11:41 (00:00) root tty1 Fri Sep 5 14:09 - 14:10 (00:01)
如果只是显示最近登录的5个帐号
#last -n 5 | awk '{print $1}'
root
root
root
dmtsai
rootawk工作流程是这样的:读入有'\n'换行符分割的一条记录,然后将记录按指定的域分隔符划分域,填充域,$0则表示所有域,$1表示第一个域,$n表示第n个域。默认域分隔符是"空白键" 或 "[tab]键",所以$1表示登录用户,$3表示登录用户ip,以此类推。
如果只是显示/etc/passwd的账户
#cat /etc/passwd |awk -F ':' '{print $1}'
root
daemon
bin
sys这种是awk+action的示例,每行都会执行action{print $1}。
-F指定域分隔符为':'。
如果只是显示/etc/passwd的账户和账户对应的shell,而账户与shell之间以tab键分割
#cat /etc/passwd |awk -F ':' '{print $1"\t"$7}'
root /bin/bash
daemon /bin/sh
bin /bin/sh
sys /bin/sh
如果只是显示/etc/passwd的账户和账户对应的shell,而账户与shell之间以逗号分割,而且在所有行添加列名name,shell,在最后一行添加"blue,/bin/nosh"。
cat /etc/passwd |awk -F ':' 'BEGIN {print "name,shell"} {print $1","$7} END {print "blue,/bin/nosh"}'
name,shell
root,/bin/bash
daemon,/bin/sh
bin,/bin/sh
sys,/bin/sh
....
blue,/bin/noshTable 1. awk的环境变量
| 变量 | 描述 |
|---|---|
| $n | 当前记录的第n个字段,字段间由FS分隔。 |
| $0 | 完整的输入记录。 |
| ARGC | 命令行参数的数目。 |
| ARGIND | 命令行中当前文件的位置(从0开始算)。 |
| ARGV | 包含命令行参数的数组。 |
| CONVFMT | 数字转换格式(默认值为%.6g) |
| ENVIRON | 环境变量关联数组。 |
| ERRNO | 最后一个系统错误的描述。 |
| FIELDWIDTHS | 字段宽度列表(用空格键分隔)。 |
| FILENAME | 当前文件名。 |
| FNR | 同NR,但相对于当前文件。 |
| FS | 字段分隔符(默认是任何空格)。 |
| IGNORECASE | 如果为真,则进行忽略大小写的匹配。 |
| NF | 当前记录中的字段数。 |
| NR | 当前记录数。 |
| OFMT | 数字的输出格式(默认值是%.6g)。 |
| OFS | 输出字段分隔符(默认值是一个空格)。 |
| ORS | 输出记录分隔符(默认值是一个换行符)。 |
| RLENGTH | 由match函数所匹配的字符串的长度。 |
| RS | 记录分隔符(默认是一个换行符)。 |
| RSTART | 由match函数所匹配的字符串的第一个位置。 |
| SUBSEP | 数组下标分隔符(默认值是\034)。 |
Table 2. 运算符
| 运算符 | 描述 |
|---|---|
| = += -= *= /= %= ^= **= | 赋值 |
| ?: | C条件表达式 |
| || | 逻辑或 |
| && | 逻辑与 |
| ~ ~! | 匹配正则表达式和不匹配正则表达式 |
| < <= > >= != == | 关系运算符 |
| 空格 | 连接 |
| + - | 加,减 |
| * / & | 乘,除与求余 |
| + - ! | 一元加,减和逻辑非 |
| ^ *** | 求幂 |
| ++ -- | 增加或减少,作为前缀或后缀 |
| $ | 字段引用 |
| in | 数组成员 |
一个验证passwd文件有效性的例子
$ cat /etc/passwd | awk -F: '\
NF != 7{\
printf("line %d,does not have 7 fields:%s\n",NR,$0)}\
$1 !~ /[A-Za-z0-9]/{printf("line %d,non alpha and numeric user id:%d: %s\n,NR,$0)}\
$2 == "*" {printf("line %d, no password: %s\n",NR,$0)}'
| 1 | cat把结果输出给awk,awk把域之间的分隔符设为冒号。 |
| 2 | 如果域的数量(NF)不等于7,就执行下面的程序。 |
| 3 | printf打印字符串"line ?? does not have 7 fields",并显示该条记录。 |
| 4 | 如果第一个域没有包含任何字母和数字,printf打印“no alpha and numeric user id" ,并显示记录数和记录。 |
| 5 | 如果第二个域是一个星号,就打印字符串“no passwd”,紧跟着显示记录数和记录本身。 |
几个实例
$ awk '/^(no|so)/' test-----打印所有以模式no或so开头的行。
$ awk '/^[ns]/{print $1}' test-----如果记录以n或s开头,就打印这个记录。
$ awk '$1 ~/[0-9][0-9]$/(print $1}' test-----如果第一个域以两个数字结束就打印这个记录。
$ awk '$1 == 100 || $2 < 50' test-----如果第一个或等于100或者第二个域小于50,则打印该行。
$ awk '$1 != 10' test-----如果第一个域不等于10就打印该行。
$ awk '/test/{print $1 + 10}' test-----如果记录包含正则表达式test,则第一个域加10并打印出来。
$ awk '{print ($1 > 5 ? "ok "$1: "error"$1)}' test-----如果第一个域大于5则打印问号后面的表达式值,否则打印冒号后面的表达式值。
$ awk '/^root/,/^mysql/' test----打印以正则表达式root开头的记录到以正则表达式mysql开头的记录范围内的所有记录。如果找到一个新的正则表达式root开头的记录,则继续打印直到下一个以正则表达式mysql开头的记录为止,或到文件末尾。
Table 3. 日期和时间格式说明符
格式 描述 %a 星期几的缩写(Sun) %A 星期几的完整写法(Sunday) %b 月名的缩写(Oct) %B 月名的完整写法(October) %c 本地日期和时间 %d 十进制日期 %D 日期 08/20/99 %e 日期,如果只有一位会补上一个空格 %H 用十进制表示24小时格式的小时 %I 用十进制表示12小时格式的小时 %j 从1月1日起一年中的第几天 %m 十进制表示的月份 %M 十进制表示的分钟 %p 12小时表示法(AM/PM) %S 十进制表示的秒 %U 十进制表示的一年中的第几个星期(星期天作为一个星期的开始) %w 十进制表示的星期几(星期天是0) %W 十进制表示的一年中的第几个星期(星期一作为一个星期的开始) %x 重新设置本地日期(08/20/99) %X 重新设置本地时间(12:00:00) %y 两位数字表示的年(99) %Y 当前月份 %Z 时区(PDT) %% 百分号(%) 实例:
$ awk '{ now=strftime( "%D", systime() ); print now }' $ awk '{ now=strftime("%m/%d/%y"); print now }'
Table 4.内建数学函数
| 函数名称 | 返回值 |
|---|---|
| atan2(x,y) | y,x范围内的余切 |
| cos(x) | 余弦函数 |
| exp(x) | 求幂 |
| int(x) | 取整 |
| log(x) | 自然对数 |
| rand() | 随机数 |
| sin(x) | 正弦 |
| sqrt(x) | 平方根 |
| srand(x) | x是rand()函数的种子 |
| int(x) | 取整,过程没有舍入 |
| rand() | 产生一个大于等于0而小于1的随机数 |
在awk中还可自定义函数,格式如下:
function name ( parameter, parameter, parameter, ... ) {
statements
return expression # the return statement and expression are optional
}awk中使用NR和FNR的一些例子
http://blog.sina.com.cn/s/blog_5a3640220100b7c8.html
http://www.linuxidc.com/Linux/2012-05/61174.htm
一般在awk里面输入文件是多个时,NR==FNR才有意义,如果这个值为true,表示还在处理第一个文件。
NR==FNR 這個一般用於讀取兩個或者兩個以上的文件中,用於判斷是在讀取第一個文件。。
test.txt 10行内容
test2.txt 4行内容
awk '{print NR,FNR}' test.txt test2.txt
1 1
2 2
3 3
4 4
5 5
6 6
7 7
8 8
9 9
10 10
11 1
12 2
13 3
14 4
现在有两个文件格式如下:
#cat account
张三|000001
李四|000002
#cat cdr
000001|10
000001|20
000002|30
000002|15
想要得到的结果是将用户名,帐号和金额在同一行打印出来,如下:
张三|000001|10
张三|000001|20
李四|000002|30
李四|000002|15
执行如下代码
#awk -F \| 'NR==FNR{a[$2]=$0;next}{print a[$1]"|"$2}' account cdr
注释:
由NR=FNR为真时,判断当前读入的是第一个文件account,然后使用{a[$2]=$0;next}循环将account文件的每行记录都存入数组a,并使用$2第2个字段作为下标引用.
由NR=FNR为假时,判断当前读入了第二个文件cdr,然后跳过{a[$2]=$0;next},对第二个文件cdr的每一行都无条件执行{print a[$1]"|"$2},此时变量$1为第二个文件的第一个字段,与读入第一个文件时,采用第一个文件第二个字段$2为数组下标相同.因此可以在此使用a[$1]引用数组。
awk '{gsub(/\$/,"");gsub(/,/,"");
if ($1>=0.1 && $1<0.2) c1+=1;
else if ($1>=0.2 && $1<0.3) c2+=1;
else if ($1>=0.3 && $1<0.4) c3+=1;
else if ($1>=0.4 && $1<0.5) c4+=1;
else if ($1>=0.5 && $1<0.6) c5+=1;
else if ($1>=0.6 && $1<0.7) c6+=1;
else if ($1>=0.7 && $1<0.8) c7+=1;
else if ($1>=0.8 && $1<0.9) c8+=1;
else if ($1>=0.9 ) c9+=1;
else c10+=1; }
END {printf "%d\t%d\t%d\t%d\t%d\t%d\t%d\t%d\t%d\t%d\t",c1,c2,c3,c4,c5,c6,c7,c8,c9,c10} ' /NEW
示例/例子:
awk '{if($0~/^>.*$/) {tmp=$0; getline; if( length($0)>=200) {print tmp"\n"$0; } }}' filename
awk '{if($0~/^>.*$/) {IGNORECASE=1; if($0~/PREDICTED/) {getline;} else {print $0; getline; print $0; } }}' filename
awk '{if($0~/^>.*$/) {IGNORECASE=1; if($0~/mRNA/) {print $0; getline; print $0; } else {getline;} }}' filename
awk '{ temp=$0; getline; if($0~/unavailable/) {;} else {print temp"\n"$0;} }' filename
substr($4,20) ---> 表示是从第4个字段里的第20个字符开始,一直到设定的分隔符","结束.
substr($3,12,8) ---> 表示是从第3个字段里的第12个字符开始,截取8个字符结束.
一、awk字符串转数字
$ awk 'BEGIN{a="100";b="10test10";print (a+b+0);}'
110
只需要将变量通过”+”连接运算。自动强制将字符串转为整型。非数字变成0,发现第一个非数字字符,后面自动忽略。
二、awk数字转为字符串
$ awk 'BEGIN{a=100;b=100;c=(a""b);print c}'
100100
只需要将变量与””符号连接起来运算即可。
三、awk字符串连接操作(字符串连接;链接;串联)
$ awk 'BEGIN{a="a";b="b";c=(a""b);print c}'
ab
$ awk 'BEGIN{a="a";b="b";c=(a+b);print c}'
0
把文件中的各行串联起来:
awk 'BEGIN{xxxx="";}{xxxx=(xxxx""$0);}END{print xxxx}' temp.txt
awk 'BEGIN{xxxx="";}{xxxx=(xxxx"\",\""$0);}END{print xxxx}' temp.txt
应用1
awk -F: '{print NF}' helloworld.sh //输出文件每行有多少字段
awk -F: '{print $1,$2,$3,$4,$5}' helloworld.sh //输出前5个字段
awk -F: '{print $1,$2,$3,$4,$5}' OFS='\t' helloworld.sh //输出前5个字段并使用制表符分隔输出
awk -F: '{print NR,$1,$2,$3,$4,$5}' OFS='\t' helloworld.sh //制表符分隔输出前5个字段,并打印行号
应用2
awk -F'[:#]' '{print NF}' helloworld.sh //指定多个分隔符: #,输出每行多少字段
awk -F'[:#]' '{print $1,$2,$3,$4,$5,$6,$7}' OFS='\t' helloworld.sh //制表符分隔输出多字段
应用3
awk -F'[:#/]' '{print NF}' helloworld.sh //指定三个分隔符,并输出每行字段数
awk -F'[:#/]' '{print $1,$2,$3,$4,$5,$6,$7,$8,$9,$10,$11,$12}' helloworld.sh //制表符分隔输出多字段
应用4
计算/home目录下,普通文件的大小,使用KB作为单位
ls -l|awk 'BEGIN{sum=0} !/^d/{sum+=$5} END{print "total size is:",sum/1024,"KB"}'
ls -l|awk 'BEGIN{sum=0} !/^d/{sum+=$5} END{print "total size is:",int(sum/1024),"KB"}' //int是取整的意思
应用5
统计netstat -anp 状态为LISTEN和CONNECT的连接数量分别是多少
netstat -anp|awk '$6~/LISTEN|CONNECTED/{sum[$6]++} END{for (i in sum) printf "%-10s %-6s %-3s \n", i," ",sum[i]}'
应用6
统计/home目录下不同用户的普通文件的总数是多少?
ls -l|awk 'NR!=1 && !/^d/{sum[$3]++} END{for (i in sum) printf "%-6s %-5s %-3s \n",i," ",sum[i]}'
mysql 199
root 374
统计/home目录下不同用户的普通文件的大小总size是多少?
ls -l|awk 'NR!=1 && !/^d/{sum[$3]+=$5} END{for (i in sum) printf "%-6s %-5s %-3s %-2s \n",i," ",sum[i]/1024/1024,"MB"}'
应用7
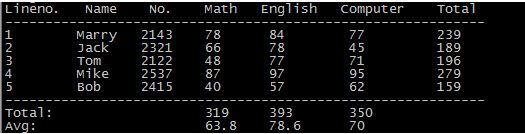
输出成绩表
awk 'BEGIN{math=0;eng=0;com=0;printf "Lineno. Name No. Math English Computer Total\n";printf "------------------------------------------------------------\n"}{math+=$3; eng+=$4; com+=$5;printf "%-8s %-7s %-7s %-7s %-9s %-10s %-7s \n",NR,$1,$2,$3,$4,$5,$3+$4+$5} END{printf "------------------------------------------------------------\n";printf "%-24s %-7s %-9s %-20s \n","Total:",math,eng,com;printf "%-24s %-7s %-9s %-20s \n","Avg:",math/NR,eng/NR,com/NR}' test0
[root@localhost home]# cat test0
Marry 2143 78 84 77
Jack 2321 66 78 45
Tom 2122 48 77 71
Mike 2537 87 97 95
Bob 2415 40 57 62
如对本文有疑问,请提交到交流论坛,广大热心网友会为你解答!! 点击进入论坛

