数据库设计三大范式和约束
数据库设计范式
什么是范式:范式, 英文名称是 Normal Form,它是英国人 E.F.Codd(关系数据库的老祖宗)在上个世纪70年代提出关系数据库模型后总结出来的,范式是关系数据库理论的基础,也是我们在设计数据库结构过程中所要遵循的规则和指导方法,简言之就是,数据库设计对数据的存储性能,还有开发人员对数据的操作都有莫大的关系。所以建立科学的,规范的的数据库是需要满足一些规范的来优化数据数据存储方式。在关系型数据库中这些规范就可以称为范式。
什么是三大范式:
第一范式:当关系模式R的所有属性都不能在分解为更基本的数据单位时,称R是满足第一范式的,简记为1NF。满足第一范式是关系模式规范化的最低要
求,否则,将有很多基本操作在这样的关系模式中实现不了。
第二范式:如果关系模式R满足第一范式,并且R得所有非主属性都完全依赖于R的每一个候选关键属性,称R满足第二范式,简记为2NF。
第三范式:设R是一个满足第一范式条件的关系模式,X是R的任意属性集,如果X非传递依赖于R的任意一个候选关键字,称R满足第三范式,简记为3NF.
注:关系实质上是一张二维表,其中每一行是一个元组,每一列是一个属性
理解三大范式
第一范式
1、每一列属性都是不可再分的属性值,确保每一列的原子性
2、两列的属性相近或相似或一样,尽量合并属性一样的列,确保不产生冗余数据。
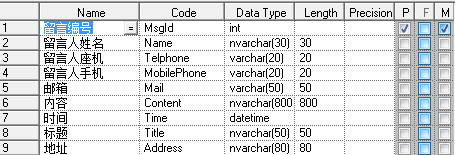
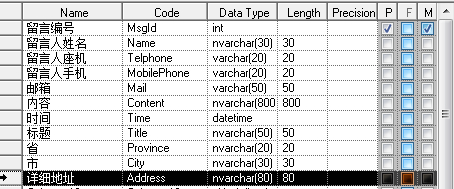
如果需求知道那个省那个市并按其分类,那么显然第一个表格是不容易满足需求的,也不符合第一范式。
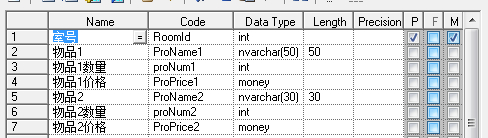

显然第一个表结构不但不能满足足够多物品的要求,还会在物品少时产生冗余。也是不符合第一范式的。
第一范式是最基本的范式。如果数据库表中的所有字段值都是不可分解的原子值,就说明该数据库表满足了第一范式。
第一范式的合理遵循需要根据系统的实际需求来定。比如某些数据库系统中需要用到“地址”这个属性,本来直接将“地址”属性设计成一个数据库表的字段就行。但是如果系统经常会访问“地址”属性中的“城市”部分,那么就非要将“地址”这个属性重新拆分为省份、城市、详细地址等多个部分进行存储,这样在对地址中某一部分操作的时候将非常方便。这样设计才算满足了数据库的第一范式,如下表所示。
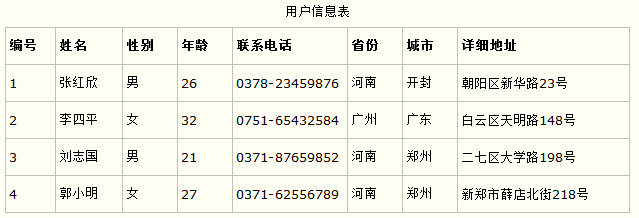
上表所示的用户信息遵循了第一范式的要求,这样在对用户使用城市进行分类的时候就非常方便,也提高了数据库的性能。
第二范式
每一行的数据只能与其中一列相关,即一行数据只做一件事。只要数据列中出现数据重复,就要把表拆分开来。
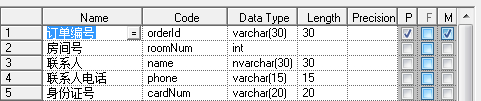
一个人同时订几个房间,就会出来一个订单号多条数据,这样子联系人都是重复的,就会造成数据冗余。我们应该把他拆开来。


这样便实现啦一条数据做一件事,不掺杂复杂的关系逻辑。同时对表数据的更新维护也更易操作。
第二范式在第一范式的基础之上更进一层。第二范式需要确保数据库表中的每一列都和主键相关,而不能只与主键的某一部分相关(主要针对联合主键而言)。也就是说在一个数据库表中,一个表中只能保存一种数据,不可以把多种数据保存在同一张数据库表中。
比如要设计一个订单信息表,因为订单中可能会有多种商品,所以要将订单编号和商品编号作为数据库表的联合主键,如下表所示。
订单信息表
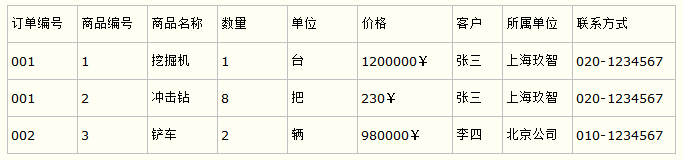
这样就产生一个问题:这个表中是以订单编号和商品编号作为联合主键。这样在该表中商品名称、单位、商品价格等信息不与该表的主键相关,而仅仅是与商品编号相关。所以在这里违反了第二范式的设计原则。
而如果把这个订单信息表进行拆分,把商品信息分离到另一个表中,把订单项目表也分离到另一个表中,就非常完美了。如下所示。
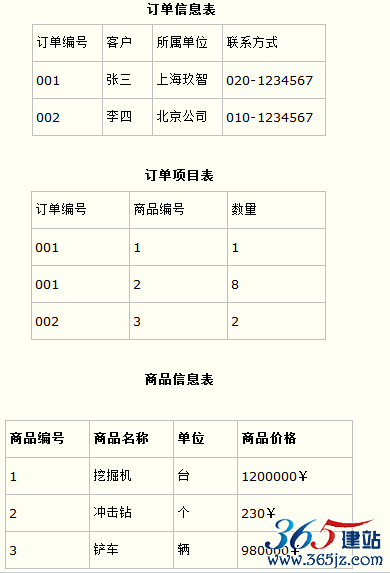
这样设计,在很大程度上减小了数据库的冗余。如果要获取订单的商品信息,使用商品编号到商品信息表中查询即可。
第三范式
数据不能存在传递关系,即没个属性都跟主键有直接关系而不是间接关系。像:a-->b-->c 属性之间含有这样的关系,是不符合第三范式的。
比如Student表(学号,姓名,年龄,性别,所在院校,院校地址,院校电话)
这样一个表结构,就存在上述关系。 学号--> 所在院校 --> (院校地址,院校电话)
这样的表结构,我们应该拆开来,如下。
(学号,姓名,年龄,性别,所在院校)--(所在院校,院校地址,院校电话)
第三范式需要确保数据表中的每一列数据都和主键直接相关,而不能间接相关。
比如在设计一个订单数据表的时候,可以将客户编号作为一个外键和订单表建立相应的关系。而不可以在订单表中添加关于客户其它信息(比如姓名、所属公司等)的字段。如下面这两个表所示的设计就是一个满足第三范式的数据库表。

这样在查询订单信息的时候,就可以使用客户编号来引用客户信息表中的记录,也不必在订单信息表中多次输入客户信息的内容,减小了数据冗余。
最后:
三大范式只是一般设计数据库的基本理念,可以建立冗余较小、结构合理的数据库。如果有特殊情况,当然要特殊对待,数据库设计最重要的是看需求跟性能,需求>性能>表结构。所以不能一味的去追求范式建立数据库。
注意事项:
1.第二范式与第三范式的本质区别:在于有没有分出两张表。
第二范式是说一张表中包含了多种不同实体的属性,那么必须要分成多张表,第三范式是要求已经分好了多张表的话,一张表中只能有另一张标的ID,而不能有其他任何信息,(其他任何信息,一律用主键在另一张表中查询)。
2.必须先满足第一范式才能满足第二范式,必须同时满足第一第二范式才能满足第三范式。
二:数据库中的五大约束:
数据库中的五大约束包括:
1.主键约束(Primay Key Coustraint) 唯一性,非空性;
2.唯一约束 (Unique Counstraint)唯一性,可以空,但只能有一个;
3.默认约束 (Default Counstraint) 该数据的默认值;
4.外键约束 (Foreign Key Counstraint) 需要建立两表间的关系;
5.非空约束(Not Null Counstraint):设置非空约束,该字段不能为空。
详细介绍:
(1)[外键约束 (Foreign Key Counstraint) ]
1.设置外键的注意事项:
①:只有INNODB的数据库引擎支持外键,修改my.ini文件设置default-storage-engine=INNODB;
②:外键与参照列的数据类型必须相同。(数值型要求长度和无符号都相同,字符串要求类型相同,长度可以不同);
③:设置外键的字段必须要有索引,如果没有索引,设置外键时会自动生成一个索引;
2.设置外键的语法:
[CONSTRAINT 外键名] FOREIGN KEY(外键字段) REFERENCES 参照表(参照字段);
[ON DELETE SET NULL ON UPDATE CASCADE] -- 设置操作完整。
3、外键约束的参照操作:
当对参照表的参照字段进行删除或更新时,外键表中的外键如何应对。
参照操作可选值:
RESTRICT: 拒绝对参照字段的删除或修改(默认);
NO ACTION:与RESTRICT相同,但这个指令只在MySql生效;
CASCADE: 删除或更新参照表的参照字段时,外键表的记录同步删除或更新;
SET NULL: 删除删除或更新参照表的参照字段时,外键表的外键设为NULL (此时外键不能设置为NOT NULL)。
(2)[主键约束](Primay Key Coustraint)
1.主键的注意事项:主键默认非空,默认唯一性约束,只有主键可以设置自动增长(主键不一定自增,自增一定是主键)。
2.设置主键的方式:
①:在定义列时设置:id INT UNSIGNED PRIMARY KEY。
②:在列定义完成后设置:PRIMARY KEY(id)。
其他约束没有特殊要求因此不做解释。
如对本文有疑问,请提交到交流论坛,广大热心网友会为你解答!! 点击进入论坛

