数据采集系统设计
前面几章讲述了ASP的开发技术,大家应该对ASP技术有了深入的了解。本章将在第5章的实验室新闻系统的基础上,学习设计一个文章采集系统。文章采集系统,顾名思义,就是采集文章内容的系统。
学习本章之前,必须对Application对象有充分的了解,如果还不熟悉Application对象,可以复习一下第2章的内容。另外,本实例将介绍一个新的组件——XMLHTTP组件。
本章重点:
l Application对象的使用方法。
l XMLHTTP组件的使用方法。
l 通过本实例的学习还可以设计音乐、影视、软件等采集系统。
6.1 系 统 概 述
6.1.1 系统功能与背景
互联网以前所未有的速度发展,成为与报纸、广播、电视相比肩的第四媒体。互联网已经悄悄进入人们的生活。眼下个人网站正如雨后春笋般涌现,但是作为个人网站没有丰富的内容,就没有大的访问量。那么一个新建立的网站,怎么才能使内容丰富呢?简单、快捷的内容采集系统便应运而生。
内容采集系统利用强大的XMLHTTP组件将庞大的互联网信息有效地采集到本地数据库,使其成为网站的内容。本章通过一个简单的实例讲述内容采集系统的设计与实现。
本例的内容采集系统主要完成如下功能。
1.栏目的管理
l 一级栏目的增加。
l 一级栏目的修改。
l 一级栏目的删除。
l 二级栏目的增加。
l 二级栏目的修改。
l 二级栏目的删除。
2.项目的管理
l 项目的增加。
l 项目的修改。
l 项目的删除。
3.历史记录管理
l 历史记录的删除。
l 历史记录的分类显示。
4.数据采集
l 数据采集主程序。
6.1.2 系统预览
图6-1是栏目的管理界面。从图中可以看出一级栏目的详细资料,包括栏目的编号、栏目的名称、栏目的描述,以及对某个栏目的操作。单击某个栏目的名字,可以进入该栏目的二级项目管理页面。
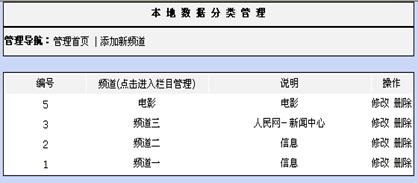
图6-1 一级栏目管理界面
图6-2是栏目的添加界面。从图中可以看出,进入栏目添加界面后可以添加一级栏目相关信息。
图6-2 一级栏目添加界面
图6-3是栏目的修改界面。从图中可以看出,进入栏目修改界面后可以修改一级栏目的相关信息。
图6-3 一级栏目修改界面
二级项目操作界面和一级栏目操作界面是一样的。
图6-4是采集项目的管理界面。从图中可以看出项目的详细信息,以及对某个项目的各种操作,包括增加、修改、删除等。
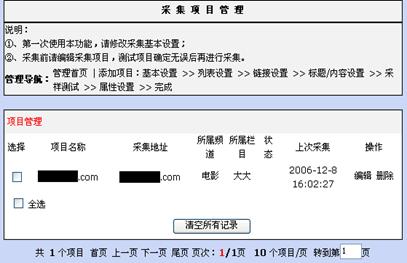
图6-4 采集项目管理的界面
图6-5是采集项目添加界面。这是项目添加的第一步——基本设置。在上面的管理导航菜单中显示了添加项目的6个步骤。

图6-5 采集项目添加界面
图6-6是修改项目的界面。从图中可以看出,修改项目的界面和添加项目的界面基本是一样的。
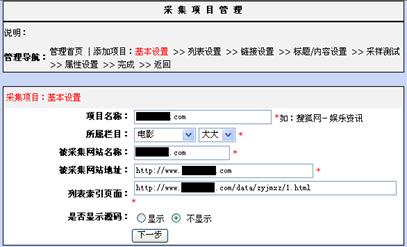
图6-6 修改项目界面
图6-7是历史记录管理界面。通过该模块可以方便地查看成功记录及失败记录。
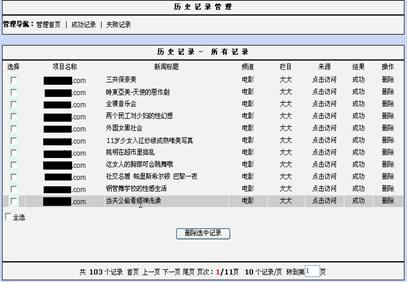
图6-7 历史记录管理界面
图6-8是项目采集数据初始化界面。系统在该页面进行数据初始化,然后自动转到数据采集页面。

图6-8 项目采集数据初始化界面
图6-9是项目采集界面。
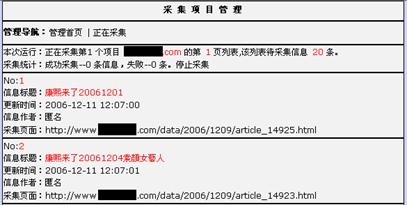
图6-9 项目采集界面
6.1.3 系统特点
本实例具有以下主要特点。
l 函数模块化:本实例在函数的设计上采用了模块化的思想。把系统中公用的功能都设计成一个模块。例如,显示分页的函数(ShowPage)、获取网页源代码函数(GetHttpPage),这些都被包含在inc/function.asp中,在开发时候只要通过<%#include file="inc/function.html"%>就可以调用了,不需要重复编写这些函数,从而提高开发效率。
l 人性化设计:本实例的导航菜单简单明了,不管用户在程序的什么页面,都可以顺利地返回或者跳转到其他页面。
l 按照软件工程的流程讲述程序设计,在设计中学习软件工程。
[NextPage]
6.2 系 统 设 计
6.2.1 系统功能模块划分
本系统是一个简单的文章采集系统,通过6.1.1节的系统功能需求分析,可以将系统细分为几个模块:栏目管理模块、项目管理模块、历史记录模块和数据采集模块4个模块。
1.栏目管理模块
录入栏目的名称、描述等信息。录入第一条记录后,系统会自动进入栏目管理主界面,以便查看录入的信息是否正确。同时可以从栏目管理界面直接进入修改或删除栏目界面,整个操作简单方便,避免了许多错误的发生。
图6-10展示了栏目系统功能模块图。
图6-10 栏目系统功能模块图
2.项目管理模块
项目管理模块和栏目管理模块一样也包括录入、修改和删除3个功能。
录入项目功能共分6步完成,包括基本设置、列表设置、链接设置、标题/内容设置、采样测试和属性设置。
基本设置包括项目的名称、所属栏目、采集网站地址。
列表设置包括设置截取列表的开始代码和结束代码,以及列表的处理类型。
链接设置包括设置截取列表的开始代码和结束代码。
标题/内容设置包括设置截取标题的开始代码和结束代码,以及截取内容的开始代码和结束代码。
采样测试是检验前面的设置是否正确。如果正确,就会显示正确的标题内容和正文内容。否则需要返回重新设置。
属性设置是设置项目的其他信息。
编辑项目功能和录入项目功能一样,也分6步。
3.历史记录模块
历史记录模块包括查看全部历史记录、成功历史记录和失败历史记录,以及删除历史记录等功能。
4.数据采集模块
数据采集模块是本系统的核心模块,通过该模块可以完成采集功能。
6.2.2 系统结构设计
根据6.2.1节的系统设计,可以得到如图6-11所示的系统结构设计图。
图6-11 系统结构设计图
这就是本系统提供的所有功能。当然,一个功能完善的采集系统还包括很多功能,例如,过滤设置、数据库导入/导出等。本示例系统提供的是一个模板,在此基础上,可以很方便地扩充其他功能
[NextPage]
6.3 数据库设计
数据库在动态程序中有着非常重要的地位,数据库结构设计的好坏将直接对应用系统的效率及实现的效果产生影响。合理的数据库结构设计可以提高数据存储的效率,保证数据的完整和一致。
设计数据库系统时应该首先充分了解用户各个方面的需求,包括现有的及将来可能增加的需求。
6.3.1 数据库逻辑设计
前面已经详细地分析了该系统所要完成的功能,因此在前面的功能清单的基础上可以很轻松地设计出本示例所需要的数据库系统。
本系统的数据结构比较简单,从分析功能清单可以知道,需要存储的是栏目信息、项目信息、历史记录信息、采集的文章信息。
栏目信息需要保存栏目ID、栏目名称和栏目描述。
项目信息需要保存项目ID、项目名称、一级栏目ID、二级栏目ID、网站名称、网站网址、列表索引页面、截取列表开始标记、截取列表结束标记、截取链接开始标记、截取链接结束标记、截取标题开始标记、截取标题结束标记、截取正文开始标记、截取正文结束标记及采集时间。如果采集类型为批量采集,还需要列表分页类型、列表分页批量类型列表索引页面、索引范围开始及索引范围结束。最后还需要一些文章的属性内容。本系统只使用编辑和内容评分。
历史记录需要保存历史ID、项目ID、一级栏目ID、二级栏目ID、文章ID、文章标题、采集时间、采集文章的源地址及是否成功标记。
文章信息需要保存文章ID、一级栏目ID、二级栏目ID、文章标题、文章内容及采集时间等基本内容。如果需要保存其他信息,还需要设计其他字段。本系统增加了编辑和文章评分两个字段。
在上面的数据库逻辑设计中列出了各个表的字段,各表的主键信息通过各表中的字段就可以看出,例如文章ID在文章信息、历史记录中都有出现,应设为文章信息的主键。
6.3.2 数据库设计
由于本系统所需的数据结构比较简单,而且数据量也不大,因此采用Access数据库作为数据库设计工具。本章将具体介绍各字段、数据类型等内容。
根据上面的数据库逻辑设计,需要设计4张数据表。由于栏目信息包括一级栏目信息和二级栏目信息,因此需要两张表来存储栏目信息,这样,本系统设计了5张数据表。
Channel表保存一级栏目信息,Class表保存二级栏目信息,Project表保存项目信息,History表保存历史记录信息,Info表保存文章信息。
1.Channel表和Class表
Channel表和Class表都包括3个字段:一个是用以标志栏目唯一性的ChannelID/ ClassID字段,数据类型采用自动编号,同时该字段也是Channel/Class表的主键;一个是栏目的名称字段ChannelName/ClassName,数据类型为文本类型;另一个是栏目的描述字段ChannelInfo/ClassInfo,数据类型为文本类型。
2.Project表
Project表包括的字段比较多,如图6-12所示。其中每个字段所代表的含义可以从图中的说明中看到。ProjectID为该表主键。
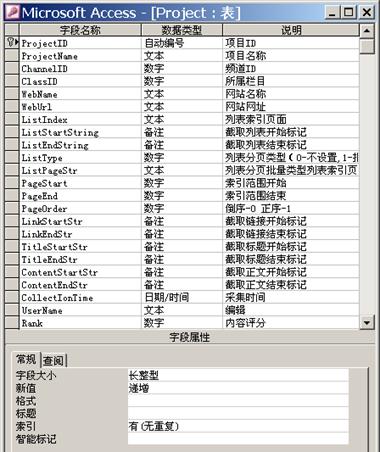
图6-12 Project表
3.History表
History表用于保存历史记录,所有字段如图6-13所示。
图6-13 History表
4.Info表
此外,还有一个Info表,用于保存采集的内容信息,所有字段如图6-14所示。
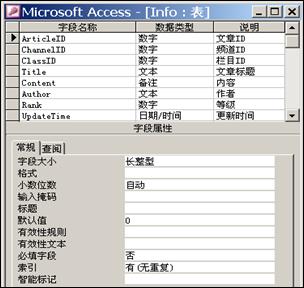
图6-14 Info表
文章采集系统采集的内容是为文章管理系统服务的,而且Info表、Channel表和Class表是文章管理系统需要的数据表,因此把它们单独保存在数据库Info中。History表和Project表是采集系统的数据表,因此把它们保存在数据库History中。
[NextPage]
6.4 系统通用功能模块设计
在程序设计过程中,有许多功能需要经常使用,比如分页的功能、错误显示功能等。在编程的时候,就需要把它们提取出来,作为单独函数,以方便调用。这些函数就是通用功能模块。这也是一种良好的编程习惯。
6.4.1 系统文件结构
为方便以后的描述,在这里将本系统的文件结构列出来,如表6-1所示。
表6-1 系统文件结构
|
文 件 名 |
所 属 目 录 |
说 明 |
|
Style.css |
/css |
样式表 |
|
Conn.asp |
/inc |
连接数据库文件 |
|
Function.asp |
/inc |
通用功能模块文件 |
|
clsCache.asp |
/inc |
缓存类文件 |
|
Channelmanage.asp |
/ |
一级栏目管理文件 |
|
Classmanage.asp |
/ |
二级栏目管理文件 |
|
Projectmanage.asp |
/ |
项目管理文件 |
|
Projectmodify.asp |
/ |
项目编辑文件 |
|
Collectmanage.asp |
/ |
采集管理文件 |
|
Collectstart.asp |
/ |
采集初始化文件 |
|
Collectinfo.asp |
/ |
采集文件 |
|
history.asp |
/ |
历史记录管理文件 |
|
Index.asp |
/ |
系统首页 |
|
Menu.asp |
/ |
系统左侧导航菜单文件 |
|
Help.asp |
/ |
系统帮助文件 |
表6-1中,所属目录“/”表示系统根目录,因此“/css”表示根目录下的css文件夹,同理“/inc”表示根目录下的inc文件夹。
6.4.2 数据库连接文件
文件conn.asp主要提供连接数据库的方法。下面主要介绍实现这些方法的代码。
在数据库设计中,设计了两个数据库,一个是保存项目信息和历史记录信息的项目数据库history.mdb,另一个是保存栏目信息和内容信息的内容数据库info.mdb。因此,设计了两个连接数据库对象:conn、connhistory。
定义和初始化连接info数据库字符串、info数据库连接对象和info数据库路径字符串变量,参考代码见例程6-1。
例程6-1 定义和初始化连接info数据库变量
dim connstr
dim db
dim Conn
db="data/info.mdb"
Set Conn = Server.CreateObject("ADODB.Connection")
connstr="Provider=Microsoft.Jet.OLEDB.4.0;Data Source=" & Server.MapPath(db)
连接info数据库,并显示出错报告,参考代码见例程6-2。
例程6-2 连接info数据库
Conn.Open connstr
If Err Then
err.Clear
Set Conn = Nothing
Response.Write "数据库连接出错,请检查连接字符串。"
Response.End
End If
关闭内容数据库对象函数,参考代码见例程6-3。
例程6-3 关闭info数据库对象函数
Sub CloseConn() '关闭数据库
Conn.close
set Conn=nothing
End sub
定义和初始化连接项目数据库字符串、项目数据库连接对象和项目数据库路径字符串变量,参考代码见例程6-4。
例程6-4 定义和初始化连接history数据库变量
dim connstrHistory
dim dbHistory
dim connHistory
dbHistory="data/history.mdb" '采集数据库文件的记录
Set connHistory = Server.CreateObject("ADODB.Connection")
connstrHistory="Provider=Microsoft.Jet.OLEDB.4.0;Data Source=" & Server.MapPath(dbHistory)
连接项目数据库,并显示出错报告,参考代码见例程6-5。
例程6-5 连接history数据库
connHistory.Open connstrHistory
If Err Then
err.Clear
Set connstrHistory = Nothing
Response.Write "采集数据库连接出错,请检查连接字符串。"
Response.End
End If
关闭项目数据库对象函数,参考代码见例程6-6。
例程6-6 关闭history数据库对象函数
Sub CloseConnHistory()
On Error Resume Next
ConnHistory.close
Set ConnHistory=nothing
End sub
6.4.3 数据缓存类文件
文件clsCache.asp是引用的一个第三方类。该类主要的功能是设置缓存,加快系统运行速度。该类主要使用Application对象来设置系统缓存。其实现的代码见例程6-7。
例程6-7 clsCache.asp
<%
'----------------------------
class clsCache
'----------------------------
private cache '缓存内容
private cacheName '缓存Application名称
private expireTime '缓存过期时间
private expireTimeName '缓存过期时间Application名称
private path '缓存页URL路径
private vaild '判断缓存是否有效
'类初始化函数,该函数在类被创建的时候自动执行
private sub class_initialize()
path=request.servervariables("url")
path=left(path,instrRev(path,"/"))
end sub
'析构函数,该函数在类被关闭的时候自动执行
private sub class_terminate()
end sub
'获取版本信息属性
Public Property Get Version
Version="Version 2004"
End Property
'获取缓存是否有效属性
public property get valid
if isempty(cache) or (not isdate(expireTime)) then
vaild=false
else
valid=true
end if
end property
'获取当前缓存内容属性
public property get value
if isempty(cache) or (not isDate(expireTime)) then
value=null
elseif CDate(expireTime)<now then
value=null
else
value=cache
end if
end property
'设置缓存名称属性
public property let name(str)
cacheName=str&path
cache=application(cacheName)
expireTimeName=str&"expire"&path
expireTime=application(expireTimeName)
end property
'设置缓存过期时间属性
public property let expire(tm)
expireTime=tm
application.Lock()
application(expireTimeName)=expireTime
application.UnLock()
end property
'对缓存赋值公用方法
public sub add(varCache,varExpireTime)
if isempty(varCache) or not isDate(varExpireTime) then
exit sub
end if
cache=varCache
expireTime=varExpireTime
application.lock
application(cacheName)=cache
application(expireTimeName)=expireTime
application.unlock
end sub
'释放缓存公用方法
public sub clean()
application.lock
application(cacheName)=empty
application(expireTimeName)=empty
application.unlock
cache=empty
expireTime=empty
end sub
'比较缓存值是否相同——返回是或否公用方法
public function verify(varcache2)
if typename(cache)<>typename(varcache2) then
verify=false
elseif typename(cache)="Object" then
if cache is varcache2 then
verify=true
else
verify=false
end if
elseif typename(cache)="Variant()" then
if join(cache,"^")=join(varcache2,"^") then
verify=true
else
verify=false
end if
else
if cache=varcache2 then
verify=true
else
verify=false
end if
end if
end function
end class
%>
下面简单介绍一下这段程序。这段代码使用了面向对象的编程方法将函数封装在一个类中。本书不是介绍面向对象的图书,因此不在这里介绍面向对象的编程方法。下面简单介绍该类中的函数。
class_initialize()类初始化函数,当类被创建后,执行该函数。
l class_terminate():析构函数,当类被销毁后,执行该函数。
l get valid():读取缓存有效性。
l get value():读取当前缓存内容。
l let name(str):设置缓存名称,参数为一个字符串,该字符串就是要设置的缓存的名称。
l let expire(tm):设置缓存过期时间,参数为一个数字,该数字就是要设置的缓存的过期时间。
l add(varCache, varExpireTime):缓存赋值函数,参数为缓存名称和过去时间。
l clean():清除缓存内容函数。
l verify(varcache2):判断缓存是否有效,参数为缓存名称。
下面介绍一下该类的使用方法。
首先,引用该文件,使用include语句,参考代码见例程6-8。
例程6-8 引用clsCache.asp
<!--#include file="inc/clsCache.html"-->
第二步,创建类,参考代码见例程6-9。
例程6-9 创建缓存类
Set ProjectCache=new clsCache
ProjectCache用于创建类的名字。
第三步,调用ProjectCache的函数,参考代码见例程6-10。
例程6-10 调用ProjectCache的函数
Call ProjectCache.clean()
这就是缓存类的使用方法。如果还没有看明白的话,没有关系,在后面的章节中还会讲到。
6.4.4 采集系统核心函数
文件function.asp主要提供内容采集系统的核心方法。下面主要介绍一下实现这些方法的代码。
在讲述这些方法之前,先介绍两个对象——XMLHTTP对象和RegExp对象。
1.XMLHTTP对象
来自MSDN的解释:XMLHTTP提供客户端同HTTP服务器通信的协议。客户端可以通过XMLHTTP对象(MSXML2.XMLHTTP.3.0)向HTTP服务器发送请求并使用微软XML文档对象模型Microsoft XML Document Object Model(DOM)处理回应。XMLHTTP最大的用处是可以更新网页的部分内容而不需要刷新整个页面。在本系统中,XMLHTTP是采集的核心组件。
1)XMLHTTP的方法
Open(bstrMethod,bstrUrl,varAsync,bstrUser,bstrPassword)
对象创建后调用Open方法对Request对象进行初始化。Open方法有5个参数,前3个是必要的,后两个是可选的(在服务器需要进行身份验证时提供)。参数的含义如表6-2所示。
表6-2 Open方法的参数含义
|
参 数 |
说 明 |
|
bstrMethod |
数据传送方式,即GET或POST |
|
bstrUrl |
服务网页的URL |
|
varAsync |
一个布尔标识,说明请求是否为异步的。如果是异步通信方式,客户端就不等待服务器的响应;如果是同步方式,客户机就要等到服务器返回消息后才去执行其他操作 |
|
bstrUser |
用户ID,用于服务器身份验证 |
|
bstrPassword |
用户密码,用于服务器身份验证 |
Send(varBody)
VarBody为指令集,可以是XML格式数据,也可以是字符串、流,或者一个无符号整数数组,也可以省略,让指令通过Open方法的URL参数代入。
Send方法的参数类型是Variant,可以是字符串、DOM树或任意数据流。发送数据的方式分为同步和异步两种。在异步方式下,数据包一旦发送完毕,就结束Send进程,客户机执行其他的操作;而在同步方式下,客户机要等到服务器返回确认消息后才结束Send进程。
2)XMLHTTP的属性
XMLHTTP的属性如表6-3所示。
表6-3 XMLHTTP的属性
|
属 性 |
说 明 |
|
readyState |
反映出服务器在处理请求时的进展状况 |
|
responseTxt |
结果返回为字符串 |
|
responseXML |
结果返回为XML格式数据 |
|
responseStream |
结果返回为Stream流 |
|
responseBody |
结果返回为无符号整数数组 |
XMLHTTP对象中的readyState属性反映出服务器在处理请求时的进展状态。客户端的程序可以根据这个状态信息设置相应的事件处理方法。其状态属性值及其含义如表6-4所示。
表6-4 readyState的状态
|
属 性 |
说 明 |
|
0 |
Response对象创建完成,但XML文档装载过程未完成 |
(续表)
|
属 性 |
说 明 |
|
1 |
XML文档装载完成 |
|
2 |
XML文档装载完成,正在处理 |
|
3 |
部分XML文档已经解析 |
|
4 |
文档已经解析完成,客户端可以接收返回消息 |
客户端只有当readyState为4后,才可以处理响应信息。客户端接收到返回消息后,进行简单的处理,基本上就完成了C/S之间的一个交互周期。
3)XMLHTTP使用步骤
首先,创建XMLHTTP对象。
第二,打开与服务端的连接,同时定义指令发送方式,服务网页(URL)和请求权限等。客户端通过Open方法打开与服务端的服务网页的连接。与普通HTTP指令传送一样,可以用GET方法或POST方法指向服务端的服务网页。
第三,用Send方法发送指令。
第四,等待并接收服务端返回的处理结果。
第五,释放XMLHTTP对象。
XMLHTTP对象是本系统的核心组件,在下面介绍其他函数时还会提到该组件的使用方法。
2.RegExp对象
RegExp对象提供简单的正则表达式支持功能。RegExp对象是全局对象,RegExp 对象不能直接创建,但始终可以使用。
1)RegExp对象的属性
RegExp对象的属性如表6-5所示。
表6-5 RegExp对象的属性
|
属 性 |
说 明 |
|
Global |
设置或返回一个布尔值,该值指明在整个搜索字符串时模式是全部匹配还是只匹配第一个。默认设置为True |
|
IgnoreCase |
设置或返回一个布尔值,指明模式搜索是否区分大小写。默认设置为True |
|
Pattern |
设置或返回被搜索的正则表达式模式 |
2)RegExp对象的方法
RegExp对象的方法如表6-6所示。
表6-6 RegExp对象的方法
|
属 性 |
说 明 |
|
Execute |
该方法对指定的字符串执行正则表达式搜索 |
|
Replace |
该方法替换在正则表达式查找中找到的文本 |
(续表)
|
属 性 |
说 明 |
|
Test |
该方法对指定的字符串执行一个正则表达式搜索,并返回一个 布尔值指示是否找到匹配的模式 |
Execute方法的正则表达式搜索的设计模式是通过RegExp对象的Pattern来设置的。该方法返回一个Matches集合,其中包含了在被搜索字符串中找到的每一个匹配的Match 对象。如果未找到匹配,Execute 将返回空的Matches集合。
Replace方法中被替换的文本的实际模式是通过RegExp对象的Pattern属性设置的。 该方法返回被搜索的字符串的副本,其中的 RegExp对象的Pattern属性已经被设置为要查找的字符串。如果没有找到匹配的文本,将返回原来的被搜索的字符串的副本。
Test方法中的正则表达式搜索的实际模式也是通过RegExp对象的Pattern属性来设置的。RegExp.Global属性对Test方法没有影响。如果找到了匹配的模式,Test方法返回True,否则返回False。
XMLHTTP对象和RegExp对象就先介绍到这里,如果不明白的话,不用担心,在以后的学习中还会用到。下面开始介绍本系统的核心函数。
3.GetHttpPage函数
首先是GetHttpPage函数。该函数通过使用XMLHTTP组件获取指定网页的源代码,参考代码见例程6-11。
例程6-11 GetHttpPage函数
1 Function GetHttpPage(HttpUrl)
2 If IsNull(HttpUrl)=True Or Len(HttpUrl)<18 Or HttpUrl="$False$" Then
3 GetHttpPage="$False$"
4 Exit Function
5 End If
6 Dim Http
7 Set Http=server.createobject("MSXML2.XMLHTTP")
8 Http.open "GET",HttpUrl,False
9 Http.Send()
10 If Http.Readystate<>4 then
11 Set Http=Nothing
12 GetHttpPage="$False$"
13 Exit function
14 End if
15 GetHTTPPage=bytesToBSTR(Http.responseBody,"GB2312")
16 Set Http=Nothing
17 If Err.number<>0 then
18 Err.Clear
19 End If
20 End Function
该函数有一个参数HttpUrl,表示要获取源代码的网页的地址。
该函数代码中,第1行是函数名声明。第2行到第5行判断参数HttpUrl是否有效,如果无效,则退出函数,输出$False$。第6行声明XMLHTTP组件名称。第7行通过server对象创建XMLHTTP组件。第8行打开与服务端的连接并设置发送方式和请求权限。Open函数的参数可以参考表6-2。第9行发送命令。第10行到第14行判断XMLHTTP的返回状态,如果不为4,就退出函数并输出$False$。这里4表示XMLHTTP对象的readyState属性返回状态。其他的返回状态可以参考表6-4。只有readyState属性返回状态为4时,客户端程序才可以处理。第15行获取源代码,并将源代码的编码转换成GB2312。转换函数BytesToBstr参考例程6-12。第16行释放XMLHTTP对象。第17行到第19行,清除错误,防止程序发生异常,导致崩溃。
4.BytesToBstr函数
BytesToBstr函数用于转换源代码的编码类型,参考代码见例程6-12。
例程6-12 BytesToBstr函数
1 Function BytesToBstr(Body,Cset)
2 Dim Objstream
3 Set Objstream = Server.CreateObject("adodb.stream")
4 objstream.Type = 1
5 objstream.Mode =3
6 objstream.Open
7 objstream.Write body
8 objstream.Position = 0
9 objstream.Type = 2
10 objstream.Charset = Cset
11 BytesToBstr = objstream.ReadText
12 objstream.Close
13 set objstream = nothing
14 End Function
该函数有两个参数。Body参数是要转换的源代码的字符串,Cset参数是转换的类型。包括GB2312,UTF-8等。在本系统中需要将源代码转换成中文编码,因此Cset为GB2312。
代码第2行定义stream对象的名称。Adodb.Stream是ADO的stream对象,提供存取二进制数据或者文本流,从而实现对流的读、写和管理等操作。第3行创建stream对象。第4行设置stream对象写入数据的类型为二进制字符流。第5行设置stream对象打开的模式。第6行打开stream对象。第7行将要转换的源代码装入对象中。第8行返加对象内数据的当前指针。第9行设置stream对象返回数据的类型文本流。第10行设置stream流返回数据的编码为Cset。第11行读取转换完成的数据并返回。第12行关闭stream对象。第13行释放stream对象。
5.GetBody函数
GetBody函数根据参数截取出需要的字符串,参考代码见例程6-13。
例程6-13 GetBody函数
1 Function GetBody(ConStr,StartStr,OverStr,IncluL,IncluR)
2 If ConStr="$False$" or ConStr="" or IsNull(ConStr)=True Or StartStr=
"" or IsNull(StartStr)=True Or OverStr="" or IsNull(OverStr)=True Then
3 GetBody="$False$"
4 Exit Function
5 End If
6 Dim ConStrTemp
7 Dim Start,Over
8 ConStrTemp=Lcase(ConStr)
9 StartStr=Lcase(StartStr)
10 OverStr=Lcase(OverStr)
11 Start = InStrB(1, ConStrTemp, StartStr, vbBinaryCompare)
12 If Start<=0 then
13 GetBody="$False$"
14 Exit Function
15 Else
16 If IncluL=False Then
17 Start=Start+LenB(StartStr)
18 End If
19 End If
20 Over=InStrB(Start,ConStrTemp,OverStr,vbBinaryCompare)
21 If Over<=0 Or Over<=Start then
22 GetBody="$False$"
23 Exit Function
24 Else
25 If IncluR=True Then
26 Over=Over+LenB(OverStr)
27 End If
28 End If
29 GetBody=MidB(ConStr,Start,Over-Start)
30 End Function
该函数有5个参数。参数ConStr是将要截取的字符串,参数StartStr设置开始字符串,参数OverStr设置结束字符串,参数IncluL设置是否包含StartStr,参数IncluR设置是否包含OverStr。
第2行到第5行判断参数是否为空,如果为空,则退出程序并返回$False$。第6行和第7行定义临时变量。第8行到第10行将ConStr、StartStr、OverStr全部转换成小写字符串。这一步是为函数InstrB准备的,因为InstrB是区分大小写的。第11行查找字符串StartStr在源字符串ConStr中首次出现的字节位置。如果字符串StartStr不能在源字符串ConStr中找到,则Start返回零。第12行到第19行判断Start是否为零,如果为零,则退出程序并返回$False$,如果不为零,设置start为截取字符串的开始位置。第16行判断IncluL是否为False,如果为False,截取字符串的开始位置并设置为start加上startStr的长度。第20行查找字符串OverStr在源字符串Constr中首次出现的字节位置。如果字符串OverStr不能在源字符串中找到,则Over返回零。第21行到第28行判断Over是否为零,如果为零,则退出程序并返回$False$,如果不为零,设置Over为截取字符串的结束位置。第25行到第27行判断IncleR是否为True,也就是说是否需要包含结束字符串,若是则设置截取字符串的结束位置为Over加上OverStr的长度。第29行使用MidB截取字符串。
6.GetArray函数
GetArray函数用于提取链接的地址,参考代码见例程6-14。
例程6-14 GetArray函数
1 Function GetArray(Byval ConStr,StartStr,OverStr,IncluL,IncluR)
2 If ConStr="$False$" or ConStr="" Or IsNull(ConStr)=True or StartStr="" Or OverStr=
"" or IsNull(StartStr)=True Or IsNull(OverStr)=True Then
3 GetArray="$False$"
4 Exit Function
5 End If
6 Dim TempStr,TempStr2,objRegExp,Matches,Match
7 TempStr=""
8 Set objRegExp = New RegExp
9 objRegExp.IgnoreCase = True
10 objRegExp.Global = True
11 objRegExp.Pattern = "("&StartStr&").+?("&OverStr&")"
12 Set Matches =objRegExp.Execute(ConStr)
13 For Each Match in Matches
14 TempStr=TempStr & "$Array$" & Match.Value
15 Next
16 Set Matches=nothing
17 If TempStr="" Then
18 GetArray="$False$"
19 Exit Function
20 End If
21 TempStr=Right(TempStr,Len(TempStr)-7)
22 If IncluL=False then
23 objRegExp.Pattern =StartStr
24 TempStr=objRegExp.Replace(TempStr,"")
25 End if
26 If IncluR=False then
27 objRegExp.Pattern =OverStr
28 TempStr=objRegExp.Replace(TempStr,"")
29 End if
30 Set objRegExp=nothing
31 Set Matches=nothing
32 TempStr=Replace(TempStr,"""","")
33 TempStr=Replace(TempStr,"'","")
34 TempStr=Replace(TempStr," ","")
35 TempStr=Replace(TempStr,"(","")
36 TempStr=Replace(TempStr,")","")
37 If TempStr="" then
38 GetArray="$False$"
39 Else
40 GetArray=TempStr
41 End if
42 End Function
该函数有5个参数。参数的意义与GetBody函数一样,这里就不一一介绍了。
函数代码第2行到第5行判断参数是否为空,若为空则退出程序并返回$False$。第6行定义临时变量。第7行初始化变量。第8行建立正则表达式。RegExp对象在本章开始已经介绍了,它不能直接创建,但始终可以用。第9行设置RegExp对象的IgnoreCase属性,区分大小写。第10行设置RegExp对象的Global属性,搜索应用于整个字符串。第11行设置RegExp对象的Pattern属性为正则表达式模式。第12行执行搜索,并返回一个Matches集合。第13行到第15行将Matches集合的元素依次写入字符串变量TempStr中,并以“$Array$”分隔。第16行释放Matches对象。第22行到第25行判断参数IncluL是否为Flase,使用RegExp对象的Replace方法用空字符串替换TempStr中的StartStr,注意在使用Replace方法的时候,RegExp对象的Pattern属性要设置为StartStr。第26行到第29行同第22行到第25行。该函数最后返回一个字符串,该字符串包含ConStr中的所有满足要求的链接。
本系统的核心函数就介绍到这里,下面介绍通用函数。
6.4.5 通用函数
1.WriteErrMsg函数
WriteErrMsg函数显示错误提示信息,参考代码见例程6-15。
例程6-15 WriteErrMsg函数
sub WriteErrMsg(ErrMsg)
dim strErr
strErr=strErr & "<html><head><title>错误信息</title><meta http-equiv='Content-Type'
content='text/html; charset=gb2312'>" & vbcrlf
strErr=strErr & "<link href='css/style.css' rel='stylesheet' type='text/css'></head><body><br><br>
" & vbcrlf
strErr=strErr & "<table cellpadding=2 cellspacing=1 border=0 width='97%' class=
'tableBorder' align=center>" & vbcrlf
strErr=strErr & " <tr align='center' class='title'><td height='22'><strong>
错误信息</strong></td></tr>" & vbcrlf
strErr=strErr & " <tr><td height='100' valign='top'><b>产生错误的可能原因:
</b>" & ErrMsg &"</td></tr>" & vbcrlf
strErr=strErr & " <tr align='center'><td><a href='javascript:history.go(-1)'><<
返回上一页</a></td></tr>" & vbcrlf
strErr=strErr & "</table>" & vbcrlf
strErr=strErr & "</body></html>" & vbcrlf
response.write strErr
end sub
这个函数主要用于程序发生错误的时候,显示错误提示信息。
2.WriteSuccessInfo函数
WriteSuccessInfo函数显示成功提示信息,参考代码见例程6-16。
例程6-16 WriteSuccessInfo函数
sub WriteSuccessInfo (SuccessMsg)
dim strErr
strErr=strErr & "<html><head><title>成功信息</title><meta http-equiv=
'Content-Type' content='text/html; charset=gb2312'>" & vbcrlf
strErr=strErr & "<link href='css/style.css' rel=
'stylesheet' type='text/css'></head><body><br><br>" & vbcrlf
strErr=strErr & "<table cellpadding=2 cellspacing=1 border=0 width='97%' class=
'tableBorder' align=center>" & vbcrlf
strErr=strErr & " <tr align='center' class='title'><td height='22'><strong>恭喜你!
</strong></td></tr>" & vbcrlf
strErr=strErr & " <tr><td height='100' valign='top' align='center'>" & SuccessMsg
&"</td></tr>" & vbcrlf
'strErr=strErr & " <tr align='center' class='tdbg'><td><a href='javascript:history.go
(-1)'><< 返回上一页</a></td></tr>" & vbcrlf
strErr=strErr & "</table>" & vbcrlf
strErr=strErr & "</body></html>" & vbcrlf
response.write strErr
end sub
这个函数主要用于程序运行成功的时候,显示成功提示信息。
3.ShowChannel_Name函数
ShowChannel_Name函数显示一级栏目名称,参考代码见例程6-17。
例程6-17 ShowChannel_Name函数
Sub ShowChannel_Name(ChannelID)
Dim Sqlc,Rsc,TempStr
ChannelID=Clng(ChannelID)
Sqlc ="select top 1 ChannelName from Channel Where ChannelID=" & ChannelID
Set Rsc=server.CreateObject("adodb.recordset")
Rsc.open Sqlc,Conn,1,1
If Rsc.Eof and Rsc.Bof then
TempStr="无指定频道"
Else
TempStr=Rsc("ChannelName")
End if
Rsc.Close
Set Rsc=Nothing
response.write TempStr
End Sub
该函数用于通过一级栏目ID查找相关的栏目信息。
4.ShowClass_Name函数
ShowClass_Name函数显示二级栏目名称,参考代码见例程6-18。
例程6-18 ShowClass_Name函数
Sub ShowClass_Name(ChannelID,ClassID)
Dim SqlC,RsC,TempStr
ChannelID=Clng(ChannelID)
ClassID=Clng(ClassID)
Sqlc ="Select top 1 ClassName from Class Where ChannelID=" & ChannelID &
" and ClassID=" & ClassID
Set RsC=server.CreateObject("adodb.recordset")
RsC.Open SqlC,Conn,1,1
If RsC.Eof And RsC.Bof Then
TempStr="无指定栏目"
Else
TempStr=RsC("ClassName")
End if
RsC.Close
Set RsC=Nothing
Response.Write TempStr
End Sub
该函数用于通过一级栏目ID和二级栏目ID查找相关的二级栏目的名称。
5.ShowPage函数
ShowPage函数提供显示页面分页内容的功能,参考代码见例程6-19。
例程6-19 ShowPage函数
'参 数:sFileName——链接地址
' TotalNumber——总数量
' MaxPerPage——每页数量
' ShowTotal——是否显示总数量
' ShowAllPages——是否用下拉列表显示所有页面以供跳转。有些页面不能使用,
' 否则会出现JS错误。
' strUnit——计数单位
Function ShowPage(sFileName,TotalNumber,MaxPerPage,ShowTotal,ShowAllPages,strUnit)
dim TotalPage,strTemp,strUrl,i
if TotalNumber=0 or MaxPerPage=0 or isNull(MaxPerPage) then
ShowPage=""
exit function
end if
if totalnumber mod maxperpage=0 then
TotalPage= totalnumber \ maxperpage
else
TotalPage= totalnumber \ maxperpage+1
end if
if CurrentPage>TotalPage then CurrentPage=TotalPage
strTemp= "<table align='center'><tr><td>"
if ShowTotal=true then
strTemp=strTemp&"共 <b>" & totalnumber & "</b> " & strUnit & " "
end if
strUrl=JoinChar(sfilename)
if CurrentPage<2 then
strTemp=strTemp & "首页 上一页 "
else
strTemp=strTemp & "<a href='" & strUrl & "page=1'>首页</a> "
strTemp=strTemp & "<a href='" & strUrl & "page=" & (CurrentPage-1) & "'>
上一页</a> "
end if
if CurrentPage>=TotalPage then
strTemp=strTemp & "下一页 尾页"
else
strTemp=strTemp & "<a href='" & strUrl & "page=" & (CurrentPage+1) & "'>
下一页</a> "
strTemp=strTemp & "<a href='" & strUrl & "page=" & TotalPage & "'>尾页</a>"
end if
strTemp=strTemp & " 页次:<strong><font color=red>" & CurrentPage&"</font>/"
& TotalPage & "</strong>页 "
strTemp=strTemp & " <b>" & maxperpage & "</b>" & strUnit & "/页"
if ShowAllPages=True then
strTemp=strTemp & " 转到第<input type='text' name='page' size='3'
maxlength='5' value='" & CurrentPage & "' onKeyPress=""if (event.keyCode==13)
window.location='" & strUrl & "page=" & "'+this.value;""'>页"
end if
strTemp=strTemp & "</td></tr></table>"
ShowPage=strTemp
End Function
6.JoinChar函数
JoinChar函数用于向地址中加入“?”或“&”,返回加了“?”或“&”的网址,参考代码见例程6-20。
例程6-20 JoinChar函数
'参 数:strUrl ——网址
function JoinChar(strUrl)
if strUrl="" then
JoinChar=""
exit function
end if
if InStr(strUrl,"?")<len(strUrl) then
if InStr(strUrl,"?")>1 then
if InStr(strUrl,"&")<len(strUrl) then
JoinChar=strUrl & "&"
else
JoinChar=strUrl
end if
else
JoinChar=strUrl & "?"
end if
else
JoinChar=strUrl
end if
end function
7.DefiniteUrl函数
DefiniteUrl函数提供将相对地址转换为绝对地址的功能,参考代码见例程6-21。
例程6-21 DefiniteUrl函数
'参 数:PrimitiveUrl ——要转换的相对地址
'参 数:ConsultUrl ——当前网页地址
Function DefiniteUrl(Byval PrimitiveUrl,Byval ConsultUrl)
Dim ConTemp,PriTemp,Pi,Ci,PriArray,ConArray
If PrimitiveUrl=""or ConsultUrl="" or PrimitiveUrl="$False$" or ConsultUrl="$False$"Then
DefiniteUrl="$False$"
Exit Function
End If
If Left(Lcase(ConsultUrl),7)<>"http://" Then
ConsultUrl= "http://" & ConsultUrl
End If
ConsultUrl=Replace(ConsultUrl,"\","/")
ConsultUrl=Replace(ConsultUrl,"://",":\\")
PrimitiveUrl=Replace(PrimitiveUrl,"\","/")
If Right(ConsultUrl,1)<>"/" Then
If Instr(ConsultUrl,"/")>0 Then
If Instr(Right(ConsultUrl,Len(ConsultUrl)-InstrRev(ConsultUrl,"/")),".")>0 then
Else
ConsultUrl=ConsultUrl & "/"
End If
Else
ConsultUrl=ConsultUrl & "/"
End If
End If
ConArray=Split(ConsultUrl,"/")
If Left(LCase(PrimitiveUrl),7) = "http://" then
DefiniteUrl=Replace(PrimitiveUrl,"://",":\\")
ElseIf Left(PrimitiveUrl,1) = "/" Then
DefiniteUrl=ConArray(0) & PrimitiveUrl
ElseIf Left(PrimitiveUrl,2)="./" Then
PrimitiveUrl=Right(PrimitiveUrl,Len(PrimitiveUrl)-2)
If Right(ConsultUrl,1)="/" Then
DefiniteUrl=ConsultUrl & PrimitiveUrl
Else
DefiniteUrl=Left(ConsultUrl,InstrRev(ConsultUrl,"/")) & PrimitiveUrl
End If
ElseIf Left(PrimitiveUrl,3)="../" then
Do While Left(PrimitiveUrl,3)="../"
PrimitiveUrl=Right(PrimitiveUrl,Len(PrimitiveUrl)-3)
Pi=Pi+1
Loop
For Ci=0 to (Ubound(ConArray)-1-Pi)
If DefiniteUrl<>"" Then
DefiniteUrl=DefiniteUrl & "/" & ConArray(Ci)
Else
DefiniteUrl=ConArray(Ci)
End If
Next
DefiniteUrl=DefiniteUrl & "/" & PrimitiveUrl
Else
If Instr(PrimitiveUrl,"/")>0 Then
PriArray=Split(PrimitiveUrl,"/")
If Instr(PriArray(0),".")>0 Then
If Right(PrimitiveUrl,1)="/" Then
DefiniteUrl="http:\\" & PrimitiveUrl
Else
If Instr(PriArray(Ubound(PriArray)-1),".")>0 Then
DefiniteUrl="http:\\" & PrimitiveUrl
Else
DefiniteUrl="http:\\" & PrimitiveUrl & "/"
End If
End If
Else
If Right(ConsultUrl,1)="/" Then
DefiniteUrl=ConsultUrl & PrimitiveUrl
Else
DefiniteUrl=Left(ConsultUrl,InstrRev(ConsultUrl,"/")) & PrimitiveUrl
End If
End If
Else
If Instr(PrimitiveUrl,".")>0 Then
If Right(ConsultUrl,1)="/" Then
If right(LCase(PrimitiveUrl),3)=".cn" or right(LCase(PrimitiveUrl),3)="com"
or right(LCase(PrimitiveUrl),3)="net"or right(LCase(PrimitiveUrl),3)="org"Then
DefiniteUrl="http:\\" & PrimitiveUrl & "/"
Else
DefiniteUrl=ConsultUrl & PrimitiveUrl
End If
Else
If right(LCase(PrimitiveUrl),3)=".cn" or right(LCase(PrimitiveUrl),3)="com"
or right(LCase(PrimitiveUrl),3)="net"or right(LCase(PrimitiveUrl),3)="org"Then
DefiniteUrl="http:\\" & PrimitiveUrl & "/"
Else
DefiniteUrl=Left(ConsultUrl,InstrRev(ConsultUrl,"/")) & "/" & PrimitiveUrl
End If
End If
Else
If Right(ConsultUrl,1)="/" Then
DefiniteUrl=ConsultUrl & PrimitiveUrl & "/"
Else
DefiniteUrl=Left(ConsultUrl,InstrRev(ConsultUrl,"/")) & "/" & PrimitiveUrl & "/"
End If
End If
End If
End If
If Left(DefiniteUrl,1)="/" then
DefiniteUrl=Right(DefiniteUrl,Len(DefiniteUrl)-1)
End if
If DefiniteUrl<>"" Then
DefiniteUrl=Replace(DefiniteUrl,"//","/")
DefiniteUrl=Replace(DefiniteUrl,":\\","://")
Else
DefiniteUrl="$False$"
End If
End Function
8.CheckUrl函数
CheckUrl函数检查网页地址是否合法,参考代码见例程6-22。
例程6-22 CheckUrl函数
'参数:strUrl——要检查的网页地址
Function CheckUrl(strUrl)
Dim Re
Set Re=new RegExp
Re.IgnoreCase =true
Re.Global=True
Re.Pattern="http://([\w-]+\.)+[\w-]+(/[\w-./?%&=]*)?"
If Re.test(strUrl)=True Then
CheckUrl=strUrl
Else
CheckUrl="$False$"
End If
Set Re=Nothing
End Function
9.ShowProject_Name函数
ShowProject_Name函数根据项目ID获取项目的名称,参考代码见例程6-23。
例程6-23 ShowProject_Name函数
'参 数:ProjectID——项目ID
Sub ShowProject_Name(ProjectID)
Dim Sqlc,Rsc,TempStr
ProjectID=Clng(ProjectID)
Sqlc ="select top 1 ProjectName from Project Where ProjectID=" & ProjectID
Set Rsc=server.CreateObject("adodb.recordset")
Rsc.open Sqlc,ConnHistory,1,1
If Rsc.Eof and Rsc.Bof then
TempStr="无指定项目"
Else
TempStr=Rsc("ProjectName")
End if
Rsc.Close
Set Rsc=Nothing
Response.Write TempStr
End Sub
[NextPage]
6.5 系统模块设计
在实现完系统的通用模块后,下面进入系统页面代码的开发。
6.5.1 栏目管理模块设计
每个网站都有一个栏目分类,好的栏目分类可以使网站的条理清晰,使阅读者能够快速地找到需要的内容,否则就会使网站杂乱无章,使阅读者很难找到需要的内容。因此一个好的栏目分类是每个网站必需的。
通过6.1.1节的功能分析可以知道,栏目管理模块包括一级栏目管理和二级栏目管理。其中每级栏目管理都包括添加、删除、修改、查看。但是通过分析可以知道,一级栏目和二级栏目实现的功能是一样的,因此,可以先考虑一级栏目的管理。一级栏目需要实现添加、删除、修改、查看等4个功能,许多初学者会认为需要使用4个页面来实现这4个功能。其实仔细看一下,这是一个典型的多分支结构,因此只需要一个页面就可以实现了。具体实现请参考例程6-24。
例程6-24 栏目管理模块实现添加、删除、修改、查看功能
<%
action =request("action")
select case action
'执行删除操作
case "del"
channelid=request("channelid")
if channelid <> "" then
sql = "delete from channel where channelid=" & channelid
Conn.execute(sql)
response.redirect("channelmanage.html")
response.end
end if
'执行修改操作
case "edit"
if request("editok")<>"" and request("editok")<>0 then
if request.form("ChannelName")="" or request.form("ChannelInfo")="" then
ErrMsg="<font color=red>请填写完整!</font>"
else
sql = "update Channel set ChannelName='" & request.form("ChannelName")
&"',ChannelInfo='" & request.form("ChannelInfo") &"' where ChannelID=
"& request.form("ChannelID")
conn.execute(sql)
Call CloseConn()
Call CloseConnHistory()
response.redirect("channelmanage.html")
response.end
end if
call edit()
else
call edit()
end if
'执行添加操作
case "add"
if request("addok")<>"" and request("addok")<>0 then
if request.form("ChannelName")="" or request.form("channelinfo")="" then
ErrMsg="<font color=red>请填写完整!</font>"
else
sql = "insert into Channel (ChannelName,channelinfo) values
('"& request.form("ChannelName")&"','"& request.form("channelinfo")&"')"
conn.execute(sql)
Call CloseConn()
Call CloseConnHistory()
response.redirect("channelmanage.html")
response.end
end if
call add()
else
call add()
end if
'执行查看操作
case else
call main()
end select
%>
系统采用select…case…语句实现了4个功能。首先需要一个变量action来判断页面需要执行的功能。例如查看图6-2所示的“添加新频道”的链接,会发现地址为“channelmanange.asp?action=add”,这就告诉该页面,需要执行添加操作。在例程6-24中,当action为“del”时,执行删除操作;当action为“edit”时,执行修改操作;当action为“add”时,执行添加操作;当action为“else”时,执行查看操作。其中,edit函数实现修改的页面显示,add函数实现添加的页面显示,main函数实现查看的页面显示。完整代码请参考文件channelmanage.asp。
|
|
select…case…语句在ASP编程中广泛用到,与if…else…一样,都用于完成多分支结构的编程。 |
6.5.2 项目管理模块设计
项目管理模块功能包括添加、修改、删除、查看。这也是一个多分支结构,可以使用select…case…语句来实现,但是由于添加和修改都需要6个步骤来完成,为使程序清楚明了,为修改操作单独设计一个页面。
添加项目的页面文件是projectmanage.asp,它主要完成项目的添加、删除和查看。
使用两个变量Del、Action来判断页面的操作。首先判断Del是否等于“Del”,如果等于,则执行删除操作并结束程序,否则判断Action是否为空,如果为空,则执行查看操作,否则执行添加操作。
主要流程如图6-15所示。
图6-15 项目管理页面流程图
其实现代码见例程6-25。
例程6-25 projectmanage.asp的主要逻辑
Action=Request.QueryString("Action")
Del=Request("Del")
if Del="Del" then
call delproject()
end if
Call Top()
Select case Action
'为空,执行查看操作
Case ""
Call Step()
'执行添加第一步
Case "Add_Project"
Call Step0()
'执行添加第二步
Case "Add_Project1"
Call Step1()
'执行添加第三步
Case "Add_Project2"
Call Step2()
'执行添加第四步
Case "Add_Project3"
Call Step3()
'执行添加第五步
Case "Add_Project4"
Call Step4()
'执行添加第六步
Case "Add_Project5"
Call Step5()
'完成添加
Case "Add_Project6"
Call Step6()
End Select
Call Bottom()
首先使用if语句判断变量Del的值,如果等于“Del”,则执行delproject函数,否则判断Action的值。如果为空,执行step函数,该函数是显示查看页面的函数,如果不为空,执行添加操作。其中Top函数用于显示页面导航,bottom函数执行关闭数据库的操作。完整实现代码见文件projectmanage.asp。
项目修改页面projectmodify.asp的实现原理与添加项目页面是一样的,只是没有删除操作和查看操作。完整实现代码见文件projectmodify.asp。
6.5.3 历史记录模块设计
历史记录模块实现历史记录的查看和删除功能。其中查看包括查看所有记录、查看失败记录和查看成功记录。
主要逻辑与项目管理模块一样。完整代码参考文件history.asp。
值得注意的是,在显示所有记录、失败记录和成功记录的时候,并不需要重复写页面代码,只需要修改SQL语句就可以完成。参考代码见例程6-26。
例程6-26 history.asp页面的SQL语句
Call Top()
Set RsHistory=server.createobject("adodb.recordset")
SqlHistory="select * from History"
If Action="Success" Then
SqlHistory=SqlHistory & " Where Result=True"
Flag="成 功 记 录"
ElseIf Action="Failure" Then
SqlHistory=SqlHistory & " Where Result=False"
Flag="失 败 记 录"
Else
Flag="所 有 记 录"
End If
当Action等于“Success”时,在SQL语句中增加“Where Result=True”就能显示成功记录,同理当Action等于“Failure”时,在SQL语句后面增加“ Where Result=False”就能显示失败记录。
|
|
按照不同的条件构建SQL语句,是一个很重要的编程技巧。 |
6.5.4 数据采集模块设计
数据采集模块是本系统最重要的一个模块。涉及到6.4.4节中的很多知识。在学习之前,最好回顾一下6.4.4节中的函数。
数据采集模块是最重要的一个模块,也是最复杂的一个模块。这个模块包括3个功能——采集管理、采集数据初始化和采集程序。下面详细介绍这3个功能。
1.采集管理
采集管理显示可以采集的项目列表,从页面上看,与项目管理页面差不多,如图6-4所示。所不同的是操作不同,项目管理的操作是编辑和删除,而采集管理的操作是采集。该操作是进入采集程序的入口。实现代码参见例程6-27。
例程6-27 采集管理程序collectmanage.asp
<%
option explicit '强制变量定义
response.buffer=true
Dim Rs,RsHistory,Sql,ErrMsg,channelid,classid,FoundErr,WebName
Dim ProjectID,ProjectNum,iProject,ProjectName,ProjectCollectionTime
Dim CurrentPage,AllPage
Const PerPage=10
%>
<!--#include file="inc/conn.html"-->
<!--#include file="inc/function.html"-->
<html>
<head>
<title>数据采集系统</title>
<meta http-equiv="Content-Type" content="text/html; charset=gb2312">
<link rel="stylesheet" type="text/css" href="css/style.css">
<style type="text/css">
<!--
.STYLE1 {
color: #000000;
font-weight: bold;
}
.STYLE2 {color: #FF0000}
-->
</style>
</head>
<body leftmargin="0" topmargin="0" marginwidth="0" marginheight="0">
<table width="97%" border="0" align="center" cellpadding="0" cellspacing="1"
class="tableBorder">
<tr>
<th height="22" colspan="2" align="center"><span class="STYLE1">采 集 项 目 管 理
</span></th>
</tr>
</table>
<table width="97%" border="0" align="center" cellpadding="0" cellspacing="1"
class="tableBorder">
<tr>
<td height="30" colspan="2">说明:<br>
①第一次使用本功能,请修改采集基本设置;<br>
②采集前请编辑采集项目,测试项目确定无误后再进行采集。
</td>
</tr>
<tr>
<td width="65" height="30"><strong>管理导航:</strong></td>
<td height="30"><a href="projectmanage.html">管理首页</a> |
<a href="projectmanage.asp?action=Add_Project">添加项目</a></td>
</tr>
</table>
<br>
<center>
<table border="0" cellpadding="0" cellspacing="0" width="97%" class="tableBorder">
<tr>
<td width="100%" height="30" valign="middle">
<font color="#FF0000">项目管理</font>
</td>
</tr>
<tr>
<td width="100%" valign="top">
<table border="0" cellspacing="1" width="100%" cellpadding="0" bgcolor="#FFFFFF">
<tr style="padding: 0px 2px;">
<td width="146" align="center">项目名称</td>
<td width="171" align="center">采集地址</td>
<td width="93" height="22" align="center">所属频道</td>
<td width="89" height="22" align="center">所属栏目</td>
<td width="44" align="center">状态</td>
<td width="145" height="22" align="center">上次采集</td>
<td width="180" height="22" align="center">操作</td>
</tr>
<%
If Request("page")<>"" then
CurrentPage=Cint(Request("Page"))
Else
CurrentPage=1
End if
Set Rs=server.createobject("adodb.recordset")
Sql="select ProjectID,ProjectName,WebName,ChannelID,ClassID from Project order by
ProjectID DESC"
Rs.open Sql,ConnHistory,1,1
'如果history数据库存在项目
if Not Rs.Eof then
Rs.PageSize=PerPage
Allpage=Rs.PageCount
If Currentpage>Allpage Then Currentpage=1
ProjectNum=Rs.RecordCount
Rs.MoveFirst
Rs.AbsolutePage=CurrentPage
iProject=0
'循环列出项目信息
Do While Not Rs.Eof
ProjectID=Rs("ProjectID")
ProjectName=Rs("ProjectName")
WebName=Rs("WebName")
ChannelID=Rs("ChannelID")
ClassID=Rs("ClassID")
%>
<tr onMouseOut="this.style.backgroundColor=''" onMouseOver="this.style.backgroundColor=
'#BFDFFF'" style="padding: 0px 2px;">
<td width="146" align="center"><%=ProjectName%></td>
<td width="171" align="center"><a href="#" target="_bank"><%=WebName%></a></td>
<td width="93"height="22"align="center"><%Call ShowChannel_Name(ChannelID)%></td>
<td width="89" align="center"><%Call ShowClass_Name(ChannelID,ClassID)%></td>
<td width="44" align="center"> <b>
</b> </td>
<td width="145" align="center">
<%
Set RsHistory=connhistory.execute("select Top 1 CollectionTime From History Where
ProjectID=" & ProjectID & " Order by HistoryID desc")
If Not Rshistory.Eof Then
ProjectCollectionTime=RsHistory("CollectionTime")
Else
ProjectCollectionTime=""
End if
Set RsHistory=Nothing
if ProjectCollectionTime<>"" then
Response.Write ProjectCollectionTime
Else
Response.Write "尚无记录"
End If
%>
</td>
<td width="180" align="center"><a href="collectstart.asp?ProjectID=
<%=ProjectID%>" target="_self">采集</a></td>
</tr>
<%
iProject=iProject+1
If iProject>=PerPage Then Exit Do
Rs.MoveNext
Loop
'如果history数据库没有项目
Else%>
<tr>
<td colspan='9' align="center"><br>
系统中暂无采集项目!</td>
</tr>
<%End If
Rs.Close
Set Rs=Nothing
%>
</table>
</td>
</tr>
</table>
<table width="100%" border="0" align="center" cellpadding="0" cellspacing="1"class="border">
<tr>
<td height="22" colspan="2" class="tdbg">
<%
'显示分页函数
Response.Write ShowPage("collectmanage.html",ProjectNum,PerPage,True,True," 个项目")
%>
</td>
</tr>
</table>
</center>
</body>
</html>
<%
Call CloseConn() '关闭info数据库
Call CloseConnHistory() '关闭history数据库
%>
2.采集数据初始化
通过单击采集管理页面的采集链接,进入采集数据初始化页面。该页面初始化采集项目需要的变量,需要采集管理页面提供项目ID。实现代码参见例程6-28。
例程6-28 采集数据初始化页面collectstart.asp
<%@LANGUAGE="VBSCRIPT" CODEPAGE="936"%>
<%
option explicit '强制变量定义
Response.Buffer = True
Server.ScriptTimeOut=10 '设置脚本超时为10秒
'关闭系统缓存
Response.Expires = -1
Response.ExpiresAbsolute = Now() - 1
Response.Expires = 0
Response.CacheControl = "no-cache"
%>
<!--#include file="inc/conn.html"-->
<!--#include file="inc/function.html"-->
<!--#include file="inc/clsCache.html"-->
<%
Dim ProjectID
Dim FoundErr,ErrMsg
Dim SqlProject,RsProject
Dim Arr_Project,Arr_History,ProjectCache
Dim CacheTemp
FoundErr=False
'设置缓存的名字,为clsCache类设置缓存的名字
CacheTemp=Lcase(trim(request.ServerVariables("SCRIPT_NAME")))
CacheTemp=left(CacheTemp,instrrev(CacheTemp,"/"))
CacheTemp=replace(CacheTemp,"\","_")
CacheTemp=replace(CacheTemp,"/","_")
CacheTemp="trsoft" & CacheTemp
'由采集管理页面传进来的项目ID
ProjectID=Request.QueryString("ProjectID")
if ProjectID="" then
FoundErr=True
ErrMsg=ErrMsg &"<br>项目编号错误!"
end if
if FoundErr<>True then
'设置缓存函数
Call SetCache()
If FoundErr<>True Then
'初始化采集项目需要的变量,使用session对象保存数据
Session("ListNum")=1 '采集链接的数目
Session("InfoSuccessNum")=0 '采集成功的文章数目
Session("InfoFalseNum")=0 '采集失败的文章数目
Session("ArticleID")=0 '采集文章的编号
'3秒钟后转入采集页面collectinfo.asp
ErrMsg="<meta http-equiv=""refresh"" content=""3;url=collectinfo.html"">"
end If
end If
if FoundErr=True then
Call WriteErrMsg(ErrMsg)
else
Call Main()
end If
'关闭数据库链接
Call CloseConn()
Call CloseConnHistory()
'写入缓存函数
Sub SetCache()
'从数据库中读取项目信息,并保存到缓存中,加快系统运行速度
SqlProject ="select * from Project where ProjectID ="&ProjectID
Set RsProject=Server.CreateObject("adodb.recordset")
RsProject.Open SqlProject,ConnHistory,1,1
If Not RsProject.Eof Then
Arr_Project=RsProject.GetRows()
End If
RsProject.Close
Set RsProject=Nothing
Set ProjectCache=new clsCache '创建缓存类 ProjectCache
ProjectCache.name=CacheTemp & "Project" '设置项目缓存类的名字
Call ProjectCache.clean() '清空缓存中的内容
If IsArray(Arr_Project)=True Then
ProjectCache.add Arr_Project,Dateadd("n",1000,now) '将数据库中获取的项目信息写入缓存
Else
FoundErr=True
ErrMsg=ErrMsg & "<br>发生意外错误!"
End If
'从数据库中读取历史记录信息,并保存到缓存中,加快系统运行速度
SqlProject ="select NewsUrl,Title,CollectionTime,Result from History"
Set RsProject=Server.CreateObject("adodb.recordset")
RsProject.Open SqlProject,ConnHistory,1,1
If Not RsProject.Eof Then
Arr_History=RsProject.GetRows()
End If
RsProject.Close
Set RsProject=Nothing
ProjectCache.name=CacheTemp & "History" '设置历史记录缓存的名字
Call ProjectCache.clean() '清空缓存
If IsArray(Arr_History)=True Then
ProjectCache.add Arr_History,Dateadd("n",1000,now) '将历史记录的信息写入缓存
End If
set ProjectCache=nothing '释放ProjectCache类
End Sub
Sub Main
%>
<html>
<head>
<title>数据采集系统</title>
<meta http-equiv="Content-Type" content="text/html; charset=gb2312">
<link rel="stylesheet" type="text/css" href="css/style.css">
<style type="text/css">
<!--
.STYLE1 {
color: #000000;
font-weight: bold;
}
.STYLE2 {color: #FF0000}
-->
</style>
</head>
<body leftmargin="0" topmargin="0" marginwidth="0" marginheight="0">
<table width="97%" border="0" align="center" cellpadding="0" cellspacing=
"1" class="tableBorder">
<tr>
<th height="22" colspan="2" align="center"><span class="STYLE1">采 集 项 目 管 理
</span></th>
</tr>
</table>
<table width="97%" border="0" align="center" cellpadding="0" cellspacing=
"1" class="tableBorder">
<tr>
<td width="65" height="30"><strong>管理导航:</strong></td>
<td height="30"><a href="collectionmanage.html">管理首页</a> >> 新闻采集 >>
初始化数据</td>
</tr>
</table>
<table width="97%" border="0" align="center" cellpadding="0"cellspacing="1"class="tableBorder">
<tr>
<td height="100" colspan="2" align=center>
<br>
欢迎使用数据采集系统,正在初始化数据,请稍后...
<br><br>
<%=ErrMsg%>
</td>
</tr>
</table>
</body>
</html>
<%End Sub%>
程序使用自定义缓存类,因此首先关闭系统缓存。实现代码参考例程6-29。
例程6-29 关闭系统缓存
Response.Expires = -1
Response.ExpiresAbsolute = Now() - 1
Response.Expires = 0
Response.CacheControl = "no-cache"
设置Response.Expires为负数或者0,就禁止了缓存。对第2个属性Response. ExpiresAbsolute的设置,允许指定在一个特殊时间到来时内容过期。本系统设置的时间比当前时间早,因此内容过期。对于HTTP代理,使用Response.CacheControl可以指示是否缓存内容。设置属性为“no-cache”,关闭代理缓存内容的功能。
系统采用的缓存类使用Application对象。因为需要为Application对象设置一个唯一的名字,本系统通过获取脚本的路径加一个变量作为Application的唯一名字。获取脚本的路径及其处理参考例程6-30。
例程6-30 获取脚本运行路径及其处理程序
CacheTemp=Lcase(trim(request.ServerVariables("SCRIPT_NAME")))
'通过request.ServerVariables获取脚本运行路径
CacheTemp=left(CacheTemp,instrrev(CacheTemp,"/"))
CacheTemp=replace(CacheTemp,"\","_") '将路径中的“/”或“\”替换为“_”
CacheTemp=replace(CacheTemp,"/","_")
CacheTemp="trsoft" & CacheTemp
由于采集项目需要从history数据库获取很多与项目相关的内容,并且每采集一条文章,都需要比较历史记录表,需要频繁读取数据库,这样就会导致系统运行速度变慢。将这些需要频繁使用的数据保存到系统缓存中,会加快系统运行速度。实现代码参见例程6-31。
例程6-31 写入缓存函数
'写入缓存函数
Sub SetCache()
'从history数据库中读取项目信息
SqlProject ="select * from Project where ProjectID ="&ProjectID
Set RsProject=Server.CreateObject("adodb.recordset")
RsProject.Open SqlProject,ConnHistory,1,1
If Not RsProject.Eof Then
Arr_Project=RsProject.GetRows() '保存到一个数组中
End If
RsProject.Close
Set RsProject=Nothing
Set ProjectCache=new clsCache '创建缓存类 ProjectCache
ProjectCache.name=CacheTemp & "Project" '设置项目缓存类的名字
Call ProjectCache.clean() '清空缓存中的内容
If IsArray(Arr_Project)=True Then
ProjectCache.add Arr_Project,Dateadd("n",1000,now) '将数据库中获取的项目信息写入缓存
Else
FoundErr=True
ErrMsg=ErrMsg & "<br>发生意外错误!"
End If
''从history数据库中读取历史记录信息
SqlProject ="select NewsUrl,Title,CollectionTime,Result from History"
Set RsProject=Server.CreateObject("adodb.recordset")
RsProject.Open SqlProject,ConnHistory,1,1
If Not RsProject.Eof Then
Arr_History=RsProject.GetRows()
End If
RsProject.Close
Set RsProject=Nothing
ProjectCache.name=CacheTemp & "History" '设置历史记录缓存的名字
Call ProjectCache.clean() '清空缓存
If IsArray(Arr_History)=True Then
ProjectCache.add Arr_History,Dateadd("n",1000,now) '将历史纪录的信息写入缓存
End If
set ProjectCache=nothing '释放ProjectCache类
End Sub
这个函数使用了6.4.3节中的clsCache类中的add函数、clean函数。实现代码参见例程6-7。
3.采集程序
采集变量初始化后,自动转入采集程序。采集程序实现采集文章的功能。采集程序是一个很复杂的过程。首先获取项目中设置的链接的索引地址,然后分析索引地址中的文章的链接地址,然后按照分析出来的地址依次采集文章。完整步骤如图6-16所示。
图6-16 采集步骤
从图6-16可以看出,完成采集程序需要两个循环结构。首先需要循环读取索引地址,流程图如图6-17所示。
图6-17 采集系统主循环流程
采集文章过程需要循环读取文章链接,流程图如图6-18所示。
图6-18 采集文章的流程图
完整实现代码参见例程6-32。
例程6-32 采集程序collectinfo.asp
<%@LANGUAGE="VBSCRIPT" CODEPAGE="936"%>
<%
option explicit
Response.Buffer = True
Server.ScriptTimeOut=999
Response.Expires = -1
Response.ExpiresAbsolute = Now() - 1
Response.Expires = 0
Response.CacheControl = "no-cache"
%>
<!--#include file="inc/conn.html"-->
<!--#include file="inc/function.html"-->
<!--#include file="inc/clsCache.html"-->
<%
'参数定义
'------------------------------------------
'项目参数
Dim ProjectID,ProjectName,ChannelID,ClassID,WebName,WebUrl
Dim ListIndex,ListStartString,ListEndString,ListType,ListPageStr,PageStart,PageEnd,PageOrder
Dim LinkStartStr,LinkEndStr,linkurl
Dim TitleStartStr,TitleEndStr,ContentStartStr,ContentEndStr
Dim CollectionTime,UserName,Rank
'出错参数
Dim Errmsg,FoundErr
'项目相关参数
Dim Arr_Project
'列表参数
Dim CollectListNum
'信息相关参数
Dim InfoSuccessNum,InfoFalseNum,CollectInfoNum,ArticleID
'采集控制参数
Dim StartTime,ListUrl,ListNum,ListEnd '采集当前列表地址,列表页面页数,当前列表是否结束
Dim CollectInfoAllNum '采集信息总数
'采集临时变量
Dim Arr_i,ListCode,Arr_InfoListCode,Arr_InfoList,InfoUrl
Dim IsCollect,Arr_History,His_i,His_Title,His_CollectionTime,His_Result
Dim InfoCode,Title,Content,UpDateTime,Author
Dim a
Dim RsHistory,SqlHistory,rs,sql
'初始化参数
'---------------------------------------------------
Dim strInstallDir,CacheTemp
strInstallDir=trim(request.ServerVariables("SCRIPT_NAME"))
strInstallDir=left(strInstallDir,instrrev(lcase(strInstallDir),"/")-1)
'strInstallDir=left(strInstallDir,instrrev(lcase(strInstallDir),"/"))
'缓存路径
CacheTemp=Lcase(trim(request.ServerVariables("SCRIPT_NAME")))
CacheTemp=left(CacheTemp,instrrev(CacheTemp,"/"))
CacheTemp=replace(CacheTemp,"\","_")
CacheTemp=replace(CacheTemp,"/","_")
CacheTemp="trsoft" & CacheTemp
'数据初始化
ListNum=Session("ListNum") '列表数目
InfoSuccessNum=Session("InfoSuccessNum") '成功采集信息数目
InfoFalseNum=Session("InfoFalseNum") '失败采集信息数目
CollectListNum=0
CollectInfoNum=0
ArticleID=Session("ArticleID") '文章ID
ErrMsg="" '错误信息
FoundErr=False '是否存在错误
ListEnd=False '列表结束
%>
<html>
<head>
<title>数据采集系统</title>
<meta http-equiv="Content-Type" content="text/html; charset=gb2312">
<link rel="stylesheet" type="text/css" href="css/style.css">
<style type="text/css">
<!--
.STYLE1 {
color: #000000;
font-weight: bold;
}
.STYLE2 {color: #FF0000}
-->
</style>
</head>
<body leftmargin="0" topmargin="0" marginwidth="0" marginheight="0">
<table width="97%" border="0" align="center" cellpadding="0" cellspacing="1"
class="tableBorder">
<tr>
<th height="22" colspan="2" align="center"><span class="STYLE1">采 集 项 目 管 理
</span></th>
</tr>
</table>
<table width="97%" border="0" align="center" cellpadding="0" cellspacing="1"
class="tableBorder">
<tr>
<td width="65" height="30"><strong>管理导航:</strong></td>
<td height="30"><a href="projectmanage.html">管理首页</a> | 正在采集</td>
</tr>
</table>
<%
Call GetCache() '读取缓存信息,包括项目和历史数据
Call SetProject() '设置项目
'程序循环开始
do While not ListEnd
FoundErr = False
ErrMsg = ""
Call SetHistoryCache()
Call SetListUrl()
if not ListEnd then
Call StartCollection()
Response.Write("<meta http-equiv=""refresh"" content=""5;url=collectinfo.html"">")
response.End()
else
dim Result
Result=""
Result=Result&"本次运行:共采集1 个项目。其中:成功采集--"&Session
("InfoSuccessNum")&"条信息,失败"&Session("InfoFalseNum")&"条。
<a href=""collectmanage.html"">停止采集</a>"
Call ShowMsg(Result)
Session("ListNum")=1
Session("InfoSuccessNum")=0
Session("InfoFalseNum")=0
Session("ArticleID")=0
end if
Loop
%>
</body>
</html>
<%
Response.Flush()
'关闭数据库链接
Call CloseConn()
Call CloseConnHistory()
'函数列表
'==================================================
'过程名:GetCache
'作 用:存取缓存
'参 数:无
'==================================================
Sub GetCache()
Dim ProjectCache
Set ProjectCache=new clsCache
'项目信息
ProjectCache.name=CacheTemp & "Project"
If ProjectCache.valid then
Arr_Project=ProjectCache.value
Else
ListEnd=True
End If
'历史记录
ProjectCache.name=CacheTemp & "History"
If ProjectCache.valid then
Arr_History=ProjectCache.value
End If
Set ProjectCache=Nothing
End Sub
'==================================================
'过程名:SetProject
'作 用:获取项目信息
'参 数:无
'==================================================
Sub SetProject()
ProjectID=Arr_Project(0,0)
ProjectName=Arr_Project(1,0) '项目名称
ChannelID=Arr_Project(2,0) '频道ID
ClassID=Arr_Project(3,0) '栏目ID
WebName=Arr_Project(4,0)
WebUrl=Arr_Project(5,0)
ListIndex=Arr_Project(6,0)
ListStartString=Arr_Project(7,0)
ListEndString=Arr_Project(8,0)
ListType=Arr_Project(9,0)
ListPageStr=Arr_Project(10,0)
PageStart=Arr_Project(11,0)
PageEnd=Arr_Project(12,0)
PageOrder=Arr_Project(13,0)
LinkStartStr=Arr_Project(14,0)
LinkEndStr=Arr_Project(15,0)
TitleStartStr=Arr_Project(16,0)
TitleEndStr=Arr_Project(17,0)
ContentStartStr=Arr_Project(18,0)
ContentEndStr=Arr_Project(19,0)
CollectionTime=Arr_Project(20,0)
UserName=Arr_Project(21,0)
Rank=Arr_Project(22,0)
End Sub
Sub DelCache()
Dim ProjectCache
Set ProjectCache=new clsCache
ProjectCache.name=CacheTemp & "Project"
Call ProjectCache.clean()
ProjectCache.name=CacheTemp & "History"
Call ProjectCache.clean()
Set ProjectCache=Nothing
End Sub
Sub SetListUrl()
If ListType=0 Then '第一种连接类型
If ListNum=1 Then
ListUrl=ListIndex
Else
ListEnd=True
End If
ElseIf ListType=1 Then
If PageStart>PageEnd then
If (PageStart-ListNum+1)<PageEnd or (PageStart-ListNum+1)<0 Then
Listend=True
Else
ListUrl=Replace(ListPageStr,"{$ID}",Cstr(PageStart-ListNum+1))
End if
Else
If (PageStart+ListNum-1)>PageEnd Then
ListEnd=True
Else
ListUrl=Replace(ListPageStr,"{$ID}",CStr(PageStart+ListNum-1))
End If
End If
End If
ListNum = ListNum + 1
End Sub
Sub StartCollection()
ListCode=GetHttpPage(ListUrl)
If ListCode="$False$" Then
FoundErr=True
ErrMsg=ErrMsg & "<br>在获取列表:" & ListUrl & "网页源码时发生错误!"
Else
ListCode=GetBody(ListCode,ListStartString,ListEndString,False,False)
If ListCode="$False$" Or ListCode="" Then
FoundErr=True
ErrMsg=ErrMsg & "<br>在截取:" & ListUrl & "的信息列表时发生错误!"
End If
End If
If FoundErr<>True Then
Arr_InfoListCode=GetArray(ListCode,LinkStartStr,LinkEndStr,False,False)
If Arr_InfoListCode="$False$" Then
FoundErr=True
ErrMsg=ErrMsg & "<br>在分析:" & ListUrl & "信息列表时发生错误!"
Else
Arr_InfoList=Split(Arr_InfoListCode,"$Array$")
For Arr_i=0 to Ubound(Arr_InfoList)
Arr_InfoList(Arr_i)=Trim(DefiniteUrl(Arr_InfoList(Arr_i),ListUrl))
Arr_InfoList(Arr_i)=CheckUrl(Arr_InfoList(Arr_i))
Next
End If
End If
if FoundErr<>True then
call CollectionInfo()
CollectInfoAllNum=0
For Arr_i=0 to Ubound(Arr_InfoList)
FoundErr = False
ErrMsg = ""
CollectInfoAllNum=CollectInfoAllNum+1
IsCollect=False
InfoUrl=Arr_InfoList(Arr_i)
If Response.IsClientConnected Then
Response.Flush
Else
Response.End
End If
'检测是否已采集
IsCollect=CheckCollect(InfoUrl)
If IsCollect=True Then
FoundErr=True
End If
If FoundErr<>True Then
InfoCode=GetHttpPage(InfoUrl)
If InfoCode="$False$" Then
FoundErr=True
ErrMsg=ErrMsg & "<br>在获取:" & InfoUrl & "信息源码时发生错误!"
Title="获取网页源码失败"
End If
End If
If FoundErr<>True Then
Title=GetBody(InfoCode,TitleStartStr,TitleEndStr,False,False)
If Title="$False$" or Title="" then
FoundErr=True
ErrMsg=ErrMsg & "<br>在分析:" & InfoUrl & "的信息标题时发生错误"
Title="<br>标题分析错误"
End If
If FoundErr<>True Then
Content=GetBody(InfoCode,ContentStartStr,ContentEndStr,False,False)
If Content="$False$" or Content="" Then
FoundErr=True
ErrMsg=ErrMsg & "<br>在分析:" & InfoUrl & "
的信息正文时发生错误"
Title=Title & "<br>正文分析错误"
End If
End If
'Title=FpHtmlEnCode(Title)
'Content=Ubbcode(Content)
UpDateTime=Now()
Author=UserName
Rank=Rank
End if
If FoundErr<>True Then
Call SaveInfo()
Call SaveHistory(1)
InfoSuccessNum=InfoSuccessNum+1
ErrMsg=ErrMsg & "No:<font color=red>" & InfoSuccessNum+InfoFalseNum
& "</font><br>"
ErrMsg=ErrMsg & "信息标题:"
ErrMsg=ErrMsg & "<font color=red>" & Title & "</font><br>"
ErrMsg=ErrMsg & "更新时间:" & UpDateTime & "<br>"
ErrMsg=ErrMsg & "信息作者:" & Author & "<br>"
ErrMsg=ErrMsg & "采集页面:<a href=" & InfoUrl & " target=_blank>
" & InfoUrl & "</a><br>"
Else
InfoFalseNum=InfoFalseNum+1
If IsCollect=True Then
ErrMsg=ErrMsg & "No:<font color=red>"
& InfoSuccessNum+InfoFalseNum & "</font><br>"
ErrMsg=ErrMsg & "目标信息:<font color=red>"
If IsCollect=True Then
ErrMsg=ErrMsg & His_Title
Else
ErrMsg=ErrMsg & InfoUrl
End If
ErrMsg=ErrMsg & "</font> 的记录已存在,不给予采集。<br>"
ErrMsg=ErrMsg & "采集时间:" & His_CollectionTime & "<br>"
ErrMsg=ErrMsg & "信息来源:<a href='" & InfoUrl &
"' target=_blank>"&InfoUrl&"</a><br>"
ErrMsg=ErrMsg & "采集结果:"
If His_Result=False Then
ErrMsg=ErrMsg & "失败"
ErrMsg=ErrMsg & "<br>失败原因:" & Title
Else
ErrMsg=ErrMsg & "成功"
End If
ErrMsg=ErrMsg & "<br>提示信息:如想再次采集,请先将该信息的历史
记录<font color=red>删除</font><br>"
End If
If IsCollect=False Then
Call SaveHistory(0)
End If
End If
Call ShowMsg(ErrMsg)
Response.Flush()'刷新
Next
Else
Call ShowMsg(ErrMsg)
End If
Session("ListNum")=ListNum
Session("InfoSuccessNum")=InfoSuccessNum
Session("InfoFalseNum")=InfoFalseNum
Session("ArticleID")=ArticleID
Response.Write "<table width=""97%"" border=""0"" align=""center"" cellpadding=
""0"" cellspacing=""1"" class=""TableBorder"">"
Response.Write "<tr><td height=""22"" colspan=""2"" align=""left"">"
Response.Write "数据整理中......<br>"
Response.Write "</td></tr></table>"
End Sub
Sub SetHistoryCache()
SqlHistory ="select NewsUrl,Title,CollectionTime,Result from History"
Set RsHistory=Server.CreateObject("adodb.recordset")
Rshistory.Open SqlHistory,ConnHistory,1,1
If Not RsHistory.Eof Then
Arr_History=RsHistory.GetRows()
End If
RsHistory.Close
Set RsHistory=Nothing
Dim HistoryCache
Set HistoryCache=new clsCache
HistoryCache.name=CacheTemp & "History"
Call HistoryCache.clean()
If IsArray(Arr_History)=True Then
HistoryCache.add Arr_History,Dateadd("n",1000,now)
End If
End Sub
Sub CollectionInfo()%>
<table width="97%" border="0" align="center" cellpadding="0" cellspacing=
"1" class="TableBorder">
<tr>
<td height="22" colspan="2" aling="left">本次运行:正在采集第1 个项目
<font color=red><%=ProjectName%></font> 的第 <font color=red><%=ListNum-1%>
</font> 页列表,该列表待采集信息
<font color=red><%=Ubound(Arr_InfoList)+1%></font> 条。
<br>采集统计:成功采集--<%=InfoSuccessNum%> 条信息,失败--<%=InfoFalseNum%>
条。<a href="collectmanage.html">停止采集</a>
</td>
</tr>
</table>
<%StartTime=Timer()
End Sub
'==================================================
'过程名:CheckCollect
'作 用:判断是否重复
'参 数:strUrl
'==================================================
Function CheckCollect(strUrl)
CheckCollect=False
If IsArray(Arr_History)=True then
For His_i=0 to Ubound(Arr_History,2)
If Arr_History(0,His_i)=strUrl Then
CheckCollect=True
His_Title=Arr_History(1,His_i)
His_CollectionTime=Arr_History(2,His_i)
His_Result=Arr_History(3,His_i)
Exit For
End If
Next
End If
End Function
'==================================================
'过程名:SaveInfo
'作 用:保存文章
'参 数:无
'==================================================
Sub SaveInfo()
If ArticleID=0 Then
set rs=server.createobject("adodb.recordset")
sql="select top 1 ArticleID from Info order by ArticleID desc"
rs.open sql,conn,1,1
If rs.eof and rs.bof then
ArticleID=1
Else
ArticleID=rs("ArticleID")+1
End If
rs.close
set rs=nothing
Else
ArticleID=ArticleID+1
End If
set rs=server.createobject("adodb.recordset")
sql="select top 1 * from Info"
rs.open sql,conn,1,3
rs.addnew
rs("ArticleID")=ArticleID
rs("ChannelID")=ChannelID
rs("ClassID")=ClassID
rs("Title")=Title
rs("Content")=Content
rs("Author")=Author
rs("Rank")=Rank
rs("UpdateTime")=UpDateTime
rs.update
rs.close
set rs=nothing
End Sub
'==================================================
'过程名:SaveHistory
'作 用:保存历史记录
'参 数:isStr 采集是否成功
'==================================================
Sub SaveHistory(isStr)
SqlHistory="INSERT INTO History(ProjectID,ChannelID,ClassID,ArticleID,
Title,CollectionTime,NewsUrl,Result) VALUES ('" & ProjectID & "','" & ChannelID & "',
'" & ClassID & "','" & ArticleID & "','" & Title & "','" & UpDateTime & "','" & InfoUrl & "',
" & isStr& ")"
ConnHistory.Execute(SqlHistory)
End Sub
'==================================================
'过程名:ShowMsg
'作 用:显示信息
'参 数:Msg 信息内容
'==================================================
Sub ShowMsg(Msg)
Dim strTemp
strTemp= "<table width=""97%"" border=""0"" align=""center"" cellpadding=
""0"" cellspacing=""1"" Class=""TableBorder"">"
strTemp=strTemp & "<tr><td height=""22"" colspan=""2"" align=""left"" id=""msg"">"
strTemp=strTemp & Msg
strTemp=strTemp & "</td></tr></table>"
Response.Write StrTemp
End Sub
%>
系统使用变量ListEnd来判断索引地址是否全部取完。主循环的实现代码参见例程6-33。
例程6-33 循环读取索引地址的实现代码
'程序循环开始
do While not ListEnd
FoundErr = False
ErrMsg = ""
Call SetHistoryCache() '读取历史记录缓存
Call SetListUrl()
'索引地址没有取完
if not ListEnd then
Call StartCollection() '采集主程序
Response.Write("<meta http-equiv=""refresh"" content=""5;url=collectinfo.html"">")
response.End() '索引地址全部取完
Else
'输出结果
dim Result
Result=""
Result=Result&"本次运行:共采集1 个项目。其中:成功采集--"&Session
("InfoSuccessNum")&"条信息,失败"&Session("InfoFalseNum")&"条。
<a href=""collectmanage.html"">停止采集</a>"
Call ShowMsg(Result)
'恢复初始化变量
Session("ListNum")=1
Session("InfoSuccessNum")=0
Session("InfoFalseNum")=0
Session("ArticleID")=0
end if
Loop
SetListUrl函数判断索引地址是否全部取完,实现代码参见例程6-34。
例程6-34 SetListUrl函数
Sub SetListUrl()
If ListType=0 Then '链接处理类型:不做处理
If ListNum=1 Then
ListUrl=ListIndex
Else
ListEnd=True
End If
ElseIf ListType=1 Then '链接处理类型:批量设置
If PageStart>PageEnd then
If (PageStart-ListNum+1)<PageEnd or (PageStart-ListNum+1)<0 Then
Listend=True
Else
ListUrl=Replace(ListPageStr,"{$ID}",Cstr(PageStart-ListNum+1))
End if
Else
If (PageStart+ListNum-1)>PageEnd Then
ListEnd=True
Else
ListUrl=Replace(ListPageStr,"{$ID}",CStr(PageStart+ListNum-1))
End If
End If
End If
ListNum = ListNum + 1
End Sub
变量ListType保存了数据库的链接处理类型,变量ListNum保存当前获取的索引链接的条目。当链接处理类型为不做处理时,索引页只有一页,因此当第二次执行SetListUrl函数时,ListEnd会被设置为“True”,循环结束。当链接处理类型为批量处理,且ListNum加一次执行SetListUrl函数时,ListEnd会被设置为“True”,循环结束。
文章采集函数StartCollection完成采集文章循环,实现代码参见例程6-35。
例程6-35 文章采集循环
Sub StartCollection()
'使用GetHttpPage函数获取网页源代码
ListCode=GetHttpPage(ListUrl)
If ListCode="$False$" Then
FoundErr=True
ErrMsg=ErrMsg & "<br>在获取列表:" & ListUrl & "网页源代码时发生错误!"
Else
ListCode=GetBody(ListCode,ListStartString,ListEndString,False,False)
If ListCode="$False$" Or ListCode="" Then
FoundErr=True
ErrMsg=ErrMsg & "<br>在截取:" & ListUrl & "的信息列表时发生错误!"
End If
End If
If FoundErr<>True Then
Arr_InfoListCode=GetArray(ListCode,LinkStartStr,LinkEndStr,False,False)
If Arr_InfoListCode="$False$" Then
FoundErr=True
ErrMsg=ErrMsg & "<br>在分析:" & ListUrl & "信息列表时发生错误!"
Else
Arr_InfoList=Split(Arr_InfoListCode,"$Array$")
For Arr_i=0 to Ubound(Arr_InfoList)
Arr_InfoList(Arr_i)=Trim(DefiniteUrl(Arr_InfoList(Arr_i),ListUrl))
Arr_InfoList(Arr_i)=CheckUrl(Arr_InfoList(Arr_i))
Next
End If
End If
if FoundErr<>True then
call CollectionInfo()
CollectInfoAllNum=0
'循环开始
For Arr_i=0 to Ubound(Arr_InfoList)
FoundErr = False
ErrMsg = ""
CollectInfoAllNum=CollectInfoAllNum+1
IsCollect=False
InfoUrl=Arr_InfoList(Arr_i)
If Response.IsClientConnected Then
Response.Flush
Else
Response.End
End If
'检测是否已采集
IsCollect=CheckCollect(InfoUrl)
If IsCollect=True Then
FoundErr=True
End If
If FoundErr<>True Then
InfoCode=GetHttpPage(InfoUrl)
If InfoCode="$False$" Then
FoundErr=True
ErrMsg=ErrMsg & "<br>在获取:"& InfoUrl &"信息源代码时发生错误!"
Title="获取网页源代码失败"
End If
End If
If FoundErr<>True Then
Title=GetBody(InfoCode,TitleStartStr,TitleEndStr,False,False)
If Title="$False$" or Title="" then
FoundErr=True
ErrMsg=ErrMsg & "<br>在分析:" & InfoUrl & "的信息标题时发生错误"
Title="<br>标题分析错误"
End If
If FoundErr<>True Then
Content=GetBody(InfoCode,ContentStartStr,ContentEndStr,False,False)
If Content="$False$" or Content="" Then
FoundErr=True
ErrMsg=ErrMsg & "<br>在分析:" & InfoUrl & "
的信息正文时发生错误"
Title=Title & "<br>正文分析错误"
End If
End If
UpDateTime=Now()
Author=UserName
Rank=Rank
End if
If FoundErr<>True Then
Call SaveInfo()
Call SaveHistory(1)
InfoSuccessNum=InfoSuccessNum+1
ErrMsg=ErrMsg & "No:<font color=red>" & InfoSuccessNum+InfoFalseNum &"
</font><br>"
ErrMsg=ErrMsg & "信息标题:"
ErrMsg=ErrMsg & "<font color=red>" & Title & "</font><br>"
ErrMsg=ErrMsg & "更新时间:" & UpDateTime & "<br>"
ErrMsg=ErrMsg & "信息作者:" & Author & "<br>"
ErrMsg=ErrMsg & "采集页面:<a href=" & InfoUrl & " target=
_blank>" & InfoUrl & "</a><br>"
Else
InfoFalseNum=InfoFalseNum+1
If IsCollect=True Then
ErrMsg=ErrMsg & "No:<font color=red>" & InfoSuccessNum+
InfoFalseNum & "</font><br>"
ErrMsg=ErrMsg & "目标信息:<font color=red>"
If IsCollect=True Then
ErrMsg=ErrMsg & His_Title
Else
ErrMsg=ErrMsg & InfoUrl
End If
ErrMsg=ErrMsg & "</font> 的记录已存在,不给予采集。<br>"
ErrMsg=ErrMsg & "采集时间:" & His_CollectionTime & "<br>"
ErrMsg=ErrMsg & "信息来源:<a href='" & InfoUrl &'
"target=_blank>"&InfoUrl&"</a><br>"
ErrMsg=ErrMsg & "采集结果:"
If His_Result=False Then
ErrMsg=ErrMsg & "失败"
ErrMsg=ErrMsg & "<br>失败原因:" & Title
Else
ErrMsg=ErrMsg & "成功"
End If
ErrMsg=ErrMsg & "<br>提示信息:如想再次采集,请先将该信息的历史
记录<font color=red>删除</font><br>"
End If
If IsCollect=False Then
Call SaveHistory(0)
End If
End If
Call ShowMsg(ErrMsg)
Response.Flush() '刷新
Next
Else
Call ShowMsg(ErrMsg)
End If
Session("ListNum")=ListNum
Session("InfoSuccessNum")=InfoSuccessNum
Session("InfoFalseNum")=InfoFalseNum
Session("ArticleID")=ArticleID
Response.Write "<table width=""97%"" border=""0"" align=""center"" cellpadding=
""0"" cellspacing=""1"" class=""TableBorder"">"
Response.Write "<tr><td height=""22"" colspan=""2"" align=""left"">"
Response.Write "数据整理中......<br>"
Response.Write "</td></tr></table>"
End Sub
StartCollection函数通过GetArray函数获取链接中的文章链接,并将其保存到变量Arr_InfoListCode中,然后使用split函数拆分变量Arr_InfoListCode,并将其保存到数组Arr_InfoList中。这样只需要知道数组Arr_InfoList的索引的最大值,就可以使用for循环完成文章采集的循环了。
例程6-32中还有许多函数,这里不一一讲解了,例程中都有注释。
至此,这个文章采集系统宣告完成,运行结果见6.1.2节。
6.6 小 结
本章介绍了如何设计和实现一个文章采集系统。该系统是一个很实用的应用程序,实际上可以采集任何类型的文章,包括文字、图片、电影等。此外,这个实例除了巩固前面课程所学习的内容之外,还阐述了XMLHTTP对象、面向对象的编程方法等重要的ASP技术,希望读者能够吸取。
本系统还有一些可以改进的地方,例如增加过滤功能,过滤采集后文章内容中的HTML代码。
如对本文有疑问,请提交到交流论坛,广大热心网友会为你解答!! 点击进入论坛

